
DisKo meets Citizens Humanities
Auf der diesjährigen Tagung des Verbands Digital Humanities im deutschsprachigen Raum (DHd) drehte sich alles um das Motto Open Humanities Open Culture. Viele spannende Projekte und Forschungsergebnisse wurden vorgestellt, wie z.B. auch unser Diversitäts-Korpus (DisKo). Wir haben Einblicke in unseren Forschungsprozess gegeben: Wie ist das Korpus aufbereitet, welche Herausforderungen entstehen beim Aufbau einer digitalen Textsammlung und wie kann eine solche valide nutzbar sowie literaturwissenschaftlich erforschbar werden? Im Anschluss haben wir diskutiert, wie zentrale Grundsätze der Einbindung von Nicht-Forschenden in wissenschaftliche Prozesse im Rahmen sogenannter “Citizen-Humanties-Projekte” (Offenheit, Transparenz und Empowerment) in die computationelle Anwendung integriert werden können.

Was ist DisKo?
DisKo steht für Diversitäts-Korpus und ist ein literaturwissenschaftliches Projekt mit Digital-Humanities-Komponente. Das Projekt ist ein Teilprojekt von m*w und widmet sich der digitalen Analyse von Genderaspekten in der Literatur. Mithilfe von Methoden des maschinellen Lernens wird ein Algorithmus trainiert, der nicht nur weibliche, männliche und neutrale Rollen in literarischen Texten erkennt, sondern auch nicht-binäre Genderzuschreibungen. Für diesen Trainingsprozess wird zunächst ein möglichst diverses Trainingskorpus aufgebaut, das aus literarischen Texten besteht, in denen nicht-binäre Geschlechterrollen vorkommen.Um Vielfalt zu gewährleisten, ist das Korpus auf diverse Leute, die an der Gestaltung teilhaben, angewiesen; auch auf Dich! Schick uns Deinen Textvorschlag und hilf uns dabei, ein Diversitäts-Korpus aufzubauen.
Wer ist beteiligt?
Am Projekt beteiligt sind Marie Flüh (Universität Hamburg), Mareike Schumacher (Universität Regensburg) und Peter Leinen (Deutsche Nationalbibliothek Frankfurt; DNB). Das Kooperationsprojekt mit der DNB geht zurück auf eine niedrigschwellige Förderinitiative, im Rahmen derer digitale Sammlungen für Wissenschaft und Forschung sowie für experimentelles und kreatives Arbeiten angeboten werden. Dies bietet für DisKo eine tolle Erweiterung der verfügbaren Ressourcen. Die DNB besitzt von jedem mit einer deutschen ISBN (Internationale Standard Buch Nummer) publizierten Werk eine analoge und/ oder digitale Version. Dies bietet für die Korpusbildung die Möglichkeit, eine quantitative Einschätzung aller deutschsprachigen Romane in der Zeitspanne von 1950 bis heute zu erhalten.
Die DNB stellt für das Projekt nicht nur Daten und Arbeitsplätze zur Verfügung, sondern lässt auch Texte digitalisieren, die bisher nur als gedrucktes Buch vorhanden sind. Da wir mit Werken arbeiten, die noch nicht gemeinfrei sind, bietet die DNB uns einen Zugang zum DNB-Intranet an. Dies bietet den Vorteil, die digitalen Texte zu analysieren und zu bearbeiten. Doch wie stellen wir aus der Vielzahl der durch die DNB bereitgestellten Werke ein Diversitäts-Korpus zusammen, das in seiner Gesamtheit eine ausbalancierte, heterogene und aussagekräftige Sammlung ergibt? Bevor die Zusammenstellung erfolgt, müssen zunächst Kriterien formuliert werden, die dazu beitragen nicht-binäre Geschlechtsdarstellungen sichtbar zu machen.
Herausforderungen beim Korpusaufbau
Die erste Herausforderung beim Aufbau eines Diversitäts-Korpus ist die grundsätzliche Frage, was genau non-binäre Genderdarstellungen ausmacht und wie Diversität in literarischen Texten abgebildet wird. Reicht es, wenn wir es mit einer nicht stereotypen Rollendarstellung zu tun haben, bei der z.B. eine männliche Figur mit einer Reihe von traditionell eher weiblich konnotierten Eigenschaften beschrieben wird? Oder muss diese Figur schon mit eindeutigen Eigenschaften wie “queerQueer Queer ist sowohl ein eigenständiges Label als auch ein Überbegriff für alle anderen queeren Identitäten.” oder “non-binär” dargestellt werden? Diese Fragen müssen bei der Textauswahl berücksichtigt werden und sind für die Abbildung von Diversität entscheidend. Eine weitere Herausforderung ist die Menge an vorliegenden Texten. Der DNB-Bestand an Romanen der letzten 100 Jahre beträgt ca. 450.000 analoge und ca. 435.000 digitale Objekte. Die bloße Auswertung der Metadaten für die Korpuskonstituierung ist nicht möglich, da es sich bei der Geschlechtsdarstellung um einen inhaltlichen Aspekt handelt, der in den Metadaten nicht erfasst ist. Dies stellt die Korpuskonstituierung vor eine dritte Herausforderung: Wir haben zu viele potenziell in Frage kommende Werke, die wir unmöglich alle selber lesen können, um im Rahmen der Lektüre zu ermitteln, in welchen Passagen non-binäre Figuren vorkommen. Zusammengefasst sind wir mit drei inhaltlichen und methodischen Problematiken konfrontiert:
- Die Grundgesamtheit kann nicht algorithmisch erschlossen werden, da nicht alle Werke digital vorliegen.
- Wir haben es bei Gender-Diversität mit einem Phänomen zu tun, das eine Interpretationsleistung erfordert.
- Der Representation-BiasRepresentation-Bias Daten, die einer Analyse zugrunde liegen, können Repräsentationsverzerrungen aufweisen – bspw., wenn Minderheiten nicht angemessen repräsentiert werden oder Stichproben nicht repräsentativ sind. muss mit einbezogen werden, daher sind grundsätzlich diverse Gruppen beim Korpusaufbau notwendig, damit am Ende nicht nur das im Korpus vertreten ist, was wir, zwei Literaturwissenschaftlerinnen, für relevant halten.
Deshalb kommen wir zu dem Schluss, dass für den Aufbau eines Diversitäts-Korpus zunächst eine Verkleinerung der (Buch-)Population durch ergänzende Kriterien unter Einbezug von geisteswissenschaftlichem Crowd-SourcingCrowd-Sourcing Auslagerung von Arbeitsschritten auf eine breite Öffentlichkeit. In den Digital Humanities bspw. bei der Transkription historischer Dokumente durch den Einbezug von Lai:innen umgesetzt. notwendig ist.
Aufbereitung des Korpus
Zur Ermittlung relevanter Buchtitel für das Diversitäts-Korpus haben wir einen öffentlichen Fragebogen konzipiert. Dieser fragt nach entsprechenden Titeln, aber auch nach der eigenen Genderzugehörigkeit sowie dem Interessenshintergrund. Die Beantwortung der letzteren Fragen ist freiwillig, für uns aber wichtig, zeigen zu können, ob es uns gelungen ist, die literatur- und kulturwissenschaftliche Bubble etwas aufzubrechen und z.B. auch Leute zu beteiligen, die sich als begeisterte Leser*innen identifizieren. Auf diese Weise kommen wir an alltagskulturell relevante Repräsentationen von Genderidentität heran. Der Einbezug der Öffentlichkeit garantiert die Diversität und Transparenz unseres DisKos. So werden die generierten Daten des Fragebogens auf unserer Website präsentiert und die Titelliste laufend erweitert. Darüber hinaus versuchen wir zu möglichst vielen Texten auch Kurzzusammenfassungen bereitzustellen, sodass sich Interessierte auch inhaltlich über unsere Textsammlung informieren können. Unter Berücksichtigung der oben genannten Herausforderungen haben wir für die Auswertung der im Fragebogen vorgeschlagenen Buchtitel drei Kriterien festgelegt:
- Kriterium der Ausbalanciertheit
- aus jedem Jahr wird zunächst nur ein Roman übernommen
- von jedem/r Autor*in wird nur ein Roman übernommen
- Kriterium der Heterogenität in Bezug auf
- literarische Genres
- Autor*innengender
- Kriterium der thematischen Relevanz: Es werden nur Romane übernommen, in denen Figuren vorkommen, die
- mit stereotypen Geschlechterrollen brechen
- sich nicht klar in ein binäres System sozialer Geschlechter fügen
Der Fragebogen (s. QR-Code) wird in drei Phasen in unterschiedlichen Communities verbreitet:
I. Phase
Die erste Phase verfolgt die Frage: Wie wird ein literaturwissenschaftliches Korpus aufgebaut, das zur Basis automatisierter Gender-Klassifikation verwendet werden soll? Die Kernzielgruppe dieser Phase ist die Digital-Humanities-Community (DH), also: Fachwissenschaftler*innen aus diesem Bereich, die hauptsächlich aufgrund der Methodik Interesse an dem Projekt haben. Als Medium der Kommunikation innerhalb dieser Community wird ein Twitter-Account aufgebaut. Dabei setzen wir auf ein organisches Wachstum, bei dem Interesse an dem Projekt über die getwitterten Inhalte ausgelöst wird. Außerdem werden weitere Informationskanäle genutzt, wie z.B. der Discord-Server DHall, die DHd-Mailingliste, der Fachinformationsdienst für Allgemeine und Vergleichende Literaturwissenschaft oder das Projektschaufenster der Webseite des DHd-Verbandes.

II. Phase
Diese Phase folgt der Frage: Was macht non-binäre Genderdarstellung aus? Hier wird der erste Outreach des Projektes generiert, indem Mitglieder der LGBTQIA+-Community angesprochen werden. Hinzukommen Personen, die über Kenntnis literarischer Texte verfügen, sodass eine Zielgruppe an der Schnittstelle zwischen LGBTQIA+-Themen und Interesse für Literatur gefunden werden muss. In dieser Phase spielt auch die Digital-Humanities-Community wieder eine entscheidende Rolle (Phase I), da Beteiligte als Multiplikator*innen im Rahmen ihrer Lehre auf das Projekt DisKo aufmerksam machen. Seitens unseres Projektes werden Gastvorträge in universitären Lehrveranstaltungen durchgeführt und Flyer in Bibliotheken ausgelegt, die mittels QR-Code auf den Fragebogen verweisen. Darüber hinaus möchten wir DisKo bei der Plattform Bürger schaffen Wissen einreichen.
III. Phase
Abschließend ist die Frage leitend: Wie bedeutsam ist non-binäre Genderdarstellung für unsere Gesellschaft? In dieser Phase setzen wir die in Citizen-Science-Ansätzen häufig sehr stark verankerte Idee einer Third Mission von Forschungsprojekten um, indem wir Ergebnisse mit einer möglichst breiten Öffentlichkeit teilen und in die aktuellen Debatten einfließen lassen. Das Thema Gender und insbesondere (Non-)Binarität wird aktuell in unterschiedlichen Bereichen des öffentlichen Lebens diskutiert. Wir gehen davon aus, dass der Genderdiskurs sowie sein Einfluss auf den alltäglichen Umgang miteinander auch in Zukunft von großer gesellschaftlicher Bedeutung sein werden. Darum suchen wir in dieser Phase weitere Wege der Wissenschaftskommunikation, wie z.B. über die Videoplattform TikTok oder den Bilder-Sharing-Dienst Instagram. Mit unserem DisKo möchten wir zeigen, dass die aktuelle Debatte nicht neu ist, sondern Gender-Diversität schon lange ein gesellschaftliches Thema ist, das sich u.a. in literarischen Texten zeigt. Unsere digitale Textsammlung veranschaulicht, dass auch in der Literaturgeschichte immer wieder Figuren eine Rolle spielen, die sich nicht in ein binäres Gendersystem fügen lassen.
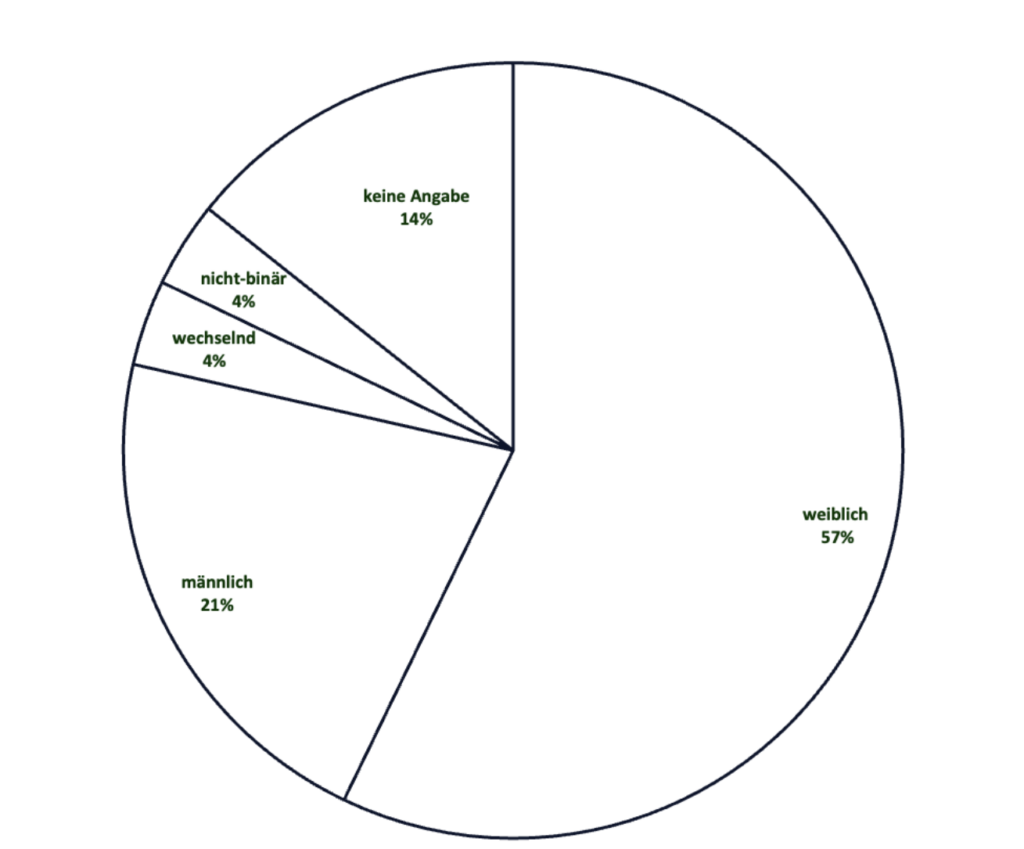
Bisherige Ergebnisse
Derzeit befinden wir uns in Phase II unseres Citizen-Humanities-Projektes DisKo. Den Fragebogen zur Ermittlung von relevanten Buchtiteln haben wir mittels Social Media (u.a. Twitter und Mastodon), der Dhd-Website und internen Kanälen der DNB sowie Flyern verbreitet. Zudem wurde ein Gastvortrag im Rahmen der Ringvorlesung Einführung in die Digital Humanities an der Universität Hamburg gehalten. Dadurch konnten wir Fachwissenschaftler*innen unser DisKo vorstellen und die Relevanz des Fragebogens erläutern. Der Rücklauf ist dennoch noch nicht sehr hoch. Insgesamt gab es 28 Teilnehmende an der Umfrage, die allerdings insgesamt 35 Titel angegeben haben. Die freiwilligen Angaben zum eigenen Hintergrund wurden meist beantwortet, wie aus dem Kuchendiagramm ersichtlich wird. Die eingereichten Titel umfassen derzeit eine Zeitspanne von 1928–2023. Der Schwerpunkt der 35 Erzähltexte liegt auf Titeln, die nach 2000 erschienen sind. Nur neunt der vorgeschlagenen Texte sind vor dem Jahr 2000 erschienen. Es handelt sich bei diesen Werken sowohl um ursprünglich deutschsprachige Erzählungen als auch um ins Deutsche übersetzte Romane.
Für die digitale Textsammlung DisKo I haben wir inzwischen eine Pilotannotationsphase beendet, in der wir insgesamt 14 Texte ausschnittsweise manuell annotiert haben. Dies reicht jedoch noch nicht für eine Sichtbarmachung von nicht-binären Genderrollen in der (deutschsprachigen) Literatur zwischen 1928 und 2023. In einer zweiten Annotationsphase widmen wir uns darum nun der Analyse kompletter Romane. Außerdem haben wir auf unserer Website eine Liste mit 71 Titeln verfasst. Zwei zusätzliche Titellisten haben wir unter dem Label DisKo+ aufbereitet und auf der Webseite publiziert. Ein Wiener Moderne Korpus und ein Korpus mit literarischen Werken, die von Simone de Beauvoir in ihrem Text “Das andere Geschlecht” erwähnt wurden.
Ausblick in die Zukunft
Auf den oben aufgezählten Ergebnisse aufbauend haben wir nun mit der Annotation vollständiger Werke begonnen. Außerdem lassen wir paketweise Titel digitalisieren, die auf unserer Liste sind, aber bisher nicht als digitale Version vorliegen. Im April diesen Jahres ist das unterstützende Unterprojekt von DisKO namens SiNG – Sichtbarmachung non-binärer Genderdarstellungen in literarischen Texten gestartet. Dafür haben wir eine Förderung der Uni Hamburg bekommen, in deren Rahmen wir die wissenschaftliche Kommunikation von DisKo weiter ausbauen und professionalisieren können. Dadurch bietet sich innerhalb der Forschung eine Möglichkeit, marginalisierte Gruppen in den Digital Humanities (DH) und darüber auch in der geisteswissenschaftlichen Forschung zu Gender zu stärken.



Das könnte dich auch interessieren

Typologisierungsversuche zur Emotionsanalyse

Tage im Leben von …
