Sprache und Emotionen in literarischen Texten
In diesem Blogbeitrag, der den zweiten Teil des Vortrags „Von Nebenbefunden und Methodenadaptionen in den Digital Humanities am Beispiel von m*w“ darstellt, werde ich näher auf den zweiten Schwerpunkt unseres Projekts eingehen. Wir möchten herausfinden, welche genderstereotypen Emotionsinformationen in novellistischen…
Von Nebenbefunden und Methodenadaptionen in den Digital Humanities am Beispiel von m*w
Wie der/die aufmerksame Leser*in weiß, untersuchen wir seit Sommer 2019 Gendersterotype und -bewertungen (in Form von Emotionen) in literarischen Texten. Im Rahmen eines Kolloquiums an der Berlin Brandenburgischen Akademie der Wissenschaften haben wir den aktuellen Stand unserer beider methodischen Schwerpunkte…
1. Analyseergebnisse: Emotionen und Gender im Deutschen Novellenschatz
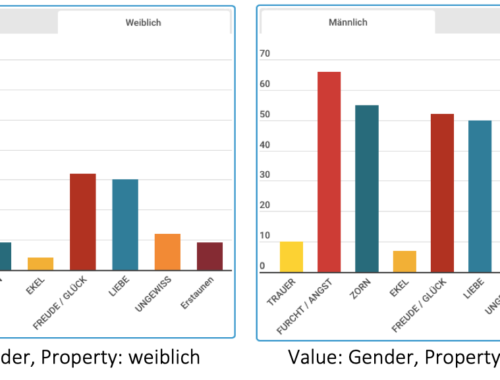
Die Analyse des ersten Drittels unseres Korpus ist geschafft. In diesem Beitrag ziehen wir eine vorsichtige Zwischenbilanz hinsichtlich einer genderstereotypen Verteilung der im Deutschen Novellenschatz verborgenen Emotionsinformationen. Zur Erinnerung: Wir möchten u. a. herausfinden, welche Emotionen männliche, weibliche oder diverse…
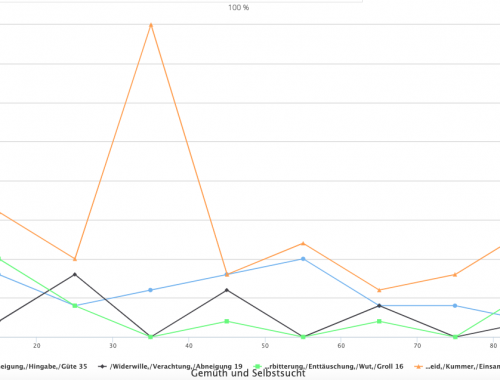
Emotionsinformationen analysieren: 3. Erste Ergebnisse – Gemüth und Selbstsucht (1787) von Margarethe von Wolff
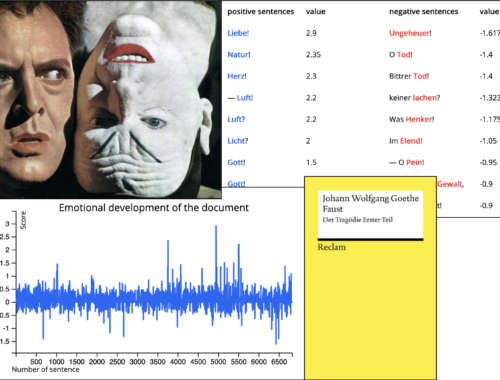
Für die Auswertung der Annotationen, die die Art der Emotion betreffen, haben wir für jedes Mitglied einer Emotionsfamilie eine Query verwendet, die die Anzahl der Tags anzeigt (Text ID 76, 20.954 Wörter, Annotation Collection Marie_Text 76). Im Text sehen die…
Emotionsinformationen analysieren: 2. Warum digital und warum CATMA?
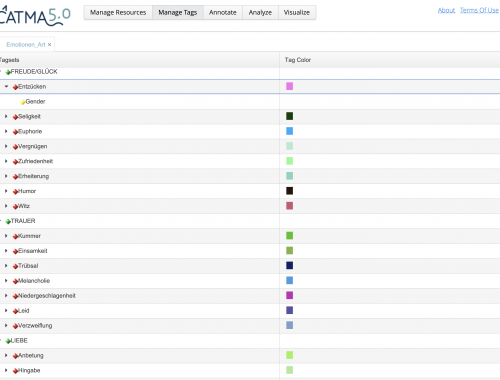
An einigen Stellen des ersten Blogbeitrags war von sog. Tagsets und Annotationen die Rede. Beide Begrifflichkeiten spielen für unser Analyseverfahren eine tragende Rolle. Die Analyse des Deutschen Novellenschatzes führen wir mithilfe des Textanalysetools CATMA (Computer Assisted Text Markup and Analysis)…