Sprache und Emotionen in literarischen Texten
In diesem Blogbeitrag, der den zweiten Teil des Vortrags „Von Nebenbefunden und Methodenadaptionen in den Digital Humanities am Beispiel von m*w“ darstellt, werde ich näher auf den zweiten Schwerpunkt unseres Projekts eingehen. Wir möchten herausfinden, welche genderstereotypen Emotionsinformationen in novellistischen Texten des 19. Jahrhunderts auftreten, ob sich stereotype Zusammenhänge zwischen Gender und Emotionen finden und ob bestehende Vorstellungen über “typisch” männliche und “typisch” weibliche Emotionskonstellationen in Frage gestellt werden müssen.
In diesem Beitrag berichte ich allerdings weniger von den Ergebnissen unserer Analyse; im Fokus der Betrachtungen stehen das methodische Vorgehen und die theoretischen Hintergründe. Dem zweiten Schwerpunkt von m*w liegt ein mixed-methods-Ansatz zugrunde, der methodische Anleihen bei den Sozial- und Informationswissenschaften sowie der traditionellen Literaturwissenschaft macht. Darüber hinaus nutzen wir unterschiedliche Verfahren, die gegenwärtig zur digitalen Analyse von literarischen Texten in den sog. Computational Literary Studies – also: in der digitalen Literaturwissenschaft – eingesetzt werden. Die methodische Leitfrage, die ich genauer erläutern werde, lautet: Mit welchen textanalytischen Verfahren können Emotionsstrukturen computergestützt aus novellistischen Texten herausgefiltert werden?
Um Ihnen die Hintergründe der Entstehung und die aktuelle Weiterentwicklung unseres Ansatzes näher zu bringen, folgt der Beitrag diesem Ablauf: Einleitend möchte ich Gedanken zur Relevanz von Emotionsanalysen zur Diskussion stellen, die unsere Projektarbeit begleiten. Dann werde ich unterschiedliche Anwendungsbereiche der Sentiment- und Emotionsanalyse in der digitalen Literaturwissenschaft vorstellen. Hierbei gehe ich auf inhaltliche Schwerpunkte sowie methodische Ausrichtungen der digitalen Emotionsanalyse ein. Darauf aufbauend stelle ich unseren Ansatz der hermeneutischen Emotionsanalyse mit CATMA vor, ziehe ein erstes Fazit und skizziere abschließend einige Gedanken zur Verbindung beider Schwerpunktbereiche.
1. Zur Relevanz literaturwissenschaftlicher Emotionsanalysen
Kommen wir zur Einleitung und der Frage danach, worin die Relevanz einer literaturwissenschaftlich ausgerichteten digitalen Emotionsanalyse liegt. Mögliche Antworten gehen – zumindest aus meiner Perspektive – zurück auf die traditionsreiche Auseinandersetzung mit Aufgaben und Gegenständen der Literaturwissenschaft (Staiger 1970), die literaturlinguistische Beschäftigung mit dem Verhältnis zwischen Sprache und Emotionen (Kalwa 2007) und auf Gedanken über die Vereinbarkeit von traditionellen Ansätzen der Literaturanalyse mit digitalen Anwendungen.
Bedeutungsvielfalt verstehen
Die durchgeführten Analysen zeigen, dass Emotionen durch unterschiedliche sprachliche Mittel konstituiert werden, die auf verschiedenen Eben der Sprache anzusiedeln sind und mal explizit, vor allem aber implizit, zutage treten. Unter literaturwissenschaftlicher Perspektive ist eine Emotionsanalyse also interessant, weil “unser Untersuchungsgegenstand” (in diesem Fall: Novellen des 19. Jahrhunderts) aus einem komplexen emotionalen Bindegewebe besteht, deren Analyse einen Teil dazu beiträgt, die Zusammensetzung und Bedeutungsvielfalt literarischer Texte besser zu verstehen und dadurch zu begreifen, was uns ergreift (Staiger: Aufgabe der Literaturwissenschaft).
Unterschiedliche Wirklichkeiten rekonstruieren
Überdies verdeutlicht eine literaturlinguistische Perspektive auf Emotionen in literarischen Texten die Relevanz der Analyse emotionstragender Textstrukturen. Grundlegend ist hierbei die Feststellung, dass durch Sprache unterschiedliche Wirklichkeiten konstruiert werden. Ein und derselbe Sachverhalt lässt sich ganz unterschiedlich beschreiben. Auf diese Weise werden mehrere Wirklichkeiten konstruiert, die wiederum unterschiedliche Emotionen evozieren (Kalwa 2015). Diese beinhalten stets eine Form der positiven oder negativen Bewertung (Schwarz-Friesel 2007, 55; zusammenfassend hier dargestellt ). Die Darstellungsweise bestimmt also in erheblichem Maße die positive oder negative Ausrichtung der Bewertung des Dargestellten. Für die Auseinandersetzung mit literarischen Texten bedeutet das zum einen (textimmanent), dass Figuren mit ihren emotionalen Verhaltensweisen eine positive (für das Wohlbefinden förderliche) oder negative (das Wohlbefinden nachteilig beeinflussende) Bewertung von Sachverhalten, ihrer Umwelt oder anderer Figuren zum Ausdruck bringen. Zum anderen stellen literarische Figuren selber bewertete Sachverhalte bzw. Objekte dar, denen unterschiedliche “emotionale Eigenschaften” zugeschrieben werden. Es stellt sich also die Frage, wie diese Figuren in Abhängigkeit zu ihrem Geschlecht beschrieben werden und welche Wirklichkeit(en) dadurch konstruiert werden. Angelehnt an den literaturlinguisitischen Ansatz zielt unser Vorgehen darauf ab, die unterschiedlichen erzählten Welten zu rekonstruieren, die durch eine homo- oder eben heterogene Zuschreibung von Emotionsinformationen entstehen können.
Methodenvielfalt nutzen
Als Aufgabe und Gegenstand der Literaturwissenschaft verstehen wir neben der inhaltlichen genderbezogenen Erschließung und der Rekonstruktion emotionaler Wirklichkeiten auch die Entwicklung einer geeigneten methodischen Herangehensweise, die unsere Interpretation transparent macht und bestehende literaturwissenschaftliche Ansätze an die aktuellen Entwicklungsschritte der Digitalen Geisteswissenschaften rückkoppelt. Unser Erkenntnisinteresse besteht also auch darin, zu begreifen, auf welche Art und Weise wir herausfinden können, was sie, die literarischen Figuren oder uns, die Leser*innen, ergreift.
Exkurs: Literaturwissenschaftliche Tradition der Emotionsanalyse
Im folgenden Teil möchte ich erläutern, mittels welcher textanalytischen Verfahren unterschiedliche emotionale Bedeutungskomponenten eines literarischen Textes identifiziert werden können.
Emotionen und Dichtung werden seit der Antike als zusammenhängende Komplexe betrachtet; philosophische Emotionstheorien existieren seit dem 17. Jhd. (Zumbusch und Koppelfels:10). Seit dem sog. “emotional turn” in den 1990er Jahren flammt in humanwissenschaftlichen Disziplinen ein neues Interesse an der Emotionsforschung auf. Hierbei werden Emotionen auf Ebene des Textprodukts, Textrezipienten oder Textproduzenten betrachtet. Daraus gehen bspw. die Regeln der Emotionalisierung erfassende Analysen (Anz, Alfes; Autoren- und Rezipientenseite), linguistische Betrachtungen zum Verhältnis von Sprache und Emotionen (Schiewers, Kawa) und kognitionspsychologische Forschungsarbeiten (Mellmann) oder eben deutlich auf das literaturwissenschaftliche Erkenntnisinteresse ausgerichtete Arbeiten (Winko, Schonlau) hervor. Die literaturwissenschaftliche Auseinandersetzung mit Emotionen und Literatur hat also durchaus eine Traditionslinie, die in der Vergangenheit ganz unterschiedliche Analyseansätze hervorgebracht hat. Wir müssen das Rad also nicht ganz neu erfinden. Aber wie steht es um digitale Ansätze der Emotionsanalyse, die der ansteigenden Anzahl an Retrodigitalisaten Rechnung tragen und eine bisher eher auf Einzelfallstudien basierende Literaturgeschichtsschreibung durch neue Perspektiven ergänzen?
Ein einziges, etabliertes operationalisierbares Verfahren zur digitalen Emotionsanalyse novellistischer Texte (oder anderer Gattungen) existiert derzeit nicht. In den Digital Humanities, bzw. dem Teilbereich der digitalen Literaturwissenschaft, greifen – wie so oft – unterschiedliche Sphären und Methoden ineinander. Anleihen kann eine digitale literaturwissenschaftliche Emotionsanalyse bei der Sentiment Analysis machen. Die bestehenden unterschiedlichen Inhalte und Methoden dieser Forschungsrichtung stelle ich kurz vor, um zu zeigen, in welcher “digitalen Traditionslinie” m*w steht.
2. Sentiment- und Emotionsanalysen in der digitalen Literaturwissenschaft
“Sentiment Analysis bezeichnet ein Forschungsfeld, bei dem mittels computergestützter Methoden versucht wird, die Meinungen, Gefühle und Emotionen von Menschen zu analysieren und vorauszusagen.“ (Liu 2016)

Sentimentanalysen bestimmen die positive, negative oder neutrale Ausrichtung – also die Polarität – von Texten. Diese Methode wird bspw. für die Überwachung Sozialer Netzwerke eingesetzt, wobei sachbezogene und meinungstragende Textanteile unterschieden und nach Polaritäten klassifiziert werden. Der Computer berechnet bspw., ob in Posts oder anderen Textformen positive oder negative Meinungen/Empfindungen geäußert werden. Auf diese Weise können bspw. Hassbotschaften gefunden und gelöscht werden. Ursprünglich gehören Sentimentanalysen also zum Methodenkanon der Informationswissenschaften, genauer: dem Text bzw. Opinion Mining.
Inhaltliche Ausrichtung von Sentiment- und Emotionsanalysen in der digitalen Literaturwissenschaft
Sentimentanalysen, die literaturwissenschaftliche Fragestellungen fokussieren, lassen sich u. a. den folgenden Forschungsschwerpunkten zuordnen (nach Kim und Klinger 2019): (1) Durch die Analysen werden Emotionen klassifiziert, die in literarischen Texte vermittelt werden. Leitend ist hierbei z.B. die Frage nach der Qualität besonders dominanter Emotionen in Abhängigkeit zur Textgattung.
(2) In eine andere Kategorie fallen Analysen, die sich mit der algorithmus-basierten Klassifizierung literarischer Werke allein auf Grundlage von Gefühlsinformationen beschäftigen.
(3) Einen weiteren inhaltlichen Schwerpunkt stellt die Nachzeichnung von Plotverläufen anhand von Emotionsinformationen dar.
(4) Wieder andere Analysen zielen darauf ab, den historischen Wandel von Emotionen in literarischen Texten zu erörtern oder emotionale Beziehungen zwischen Figuren aufzudecken.
Methodische Ausrichtung von Sentiment- und Emotionsanalysen in der digitalen Literaturwissenschaft
Kommen wir von den Inhalten zur Methodik. Bei den literaturwissenschaftlichen wie auch den kommerziellen Sentimentanalysen lassen sich aktuell zwei Methoden oder “Großformen der Sentimentanalyse”, unterscheiden (vgl. Abb. 2): Lexikonbaiserte Analysen und Verfahren, die auf Machine Learning-Ansätze zurückgreifen (Schmidt et al. 2018).
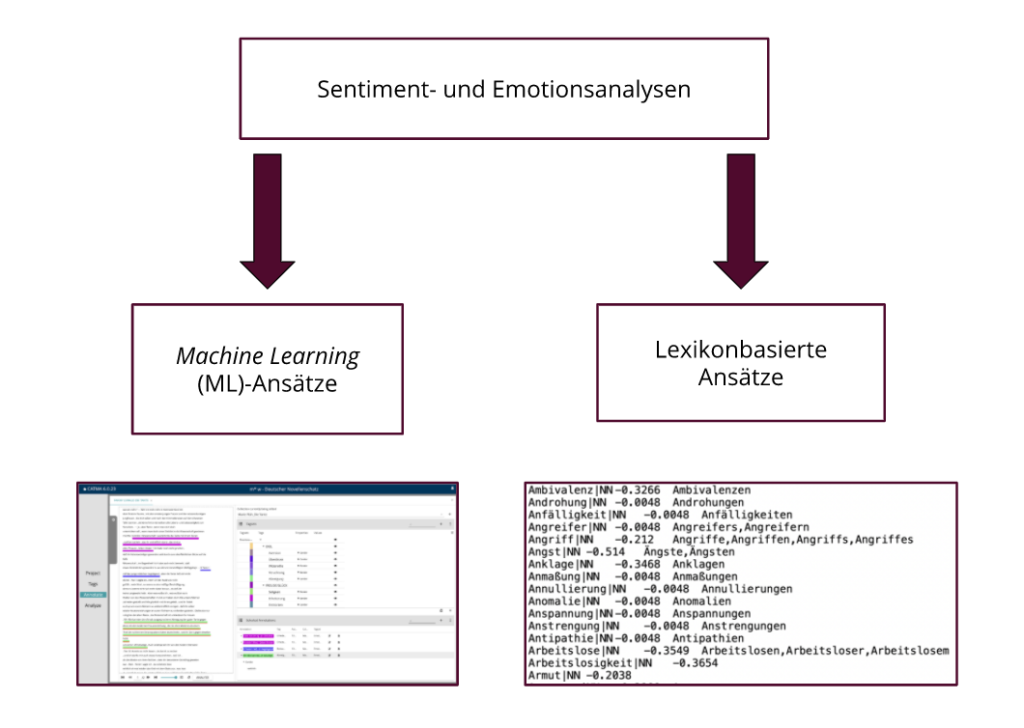
Lexikonabsierte Sentimentanalyse
Anders als bei Ansätzen, die auf Machine Learning zurückgreifen, handelt es sich um ein unüberwachtes Verfahren, welches keine annotierten Trainingsdaten benötigt. Lexikonbasierte Ansätze gehen von der theoretischen Annahme aus, dass das Sentiment eines Dokuments oder Satzes auf Basis der Sentiment-Ausrichtung der einzelnen Wörter oder Phrasen bestimmt werden kann (vgl. Schmidt, Burghardt, Wolff 2018). Im Rahmen der Analyse findet ein Wortabgleich zwischen einem Primärtext oder einem Textkorpus und einem Sentimentwörterbuch statt (vgl. Abb. 3). Hierbei handelt es sich um Lexika, die ausschließlich sentiment- oder empfindungstragende Lexeme enthalten. Für jedes Wort wird ein Sentimentwert berechnet; der Sentimentwert oder Sentimentgehalt eines Wortes drückt in einer Skala von –1 (maximal negativ) bis +1 (maximal positiv) die Polarität der Sentimentwörter aus. Durch den Abgleich zwischen Primärtext und Wörterbuch wird schlussendlich die Polarität eines Wortes, Satzes oder Dokuments berechnet. Die Gesamtpolarität ergibt sich aus der Summe der Polaritätswerte der einzelnen im Text erkannten Sentiment Bearing Words.

Lexikonbasierte Sentimentanalyse mit SentText
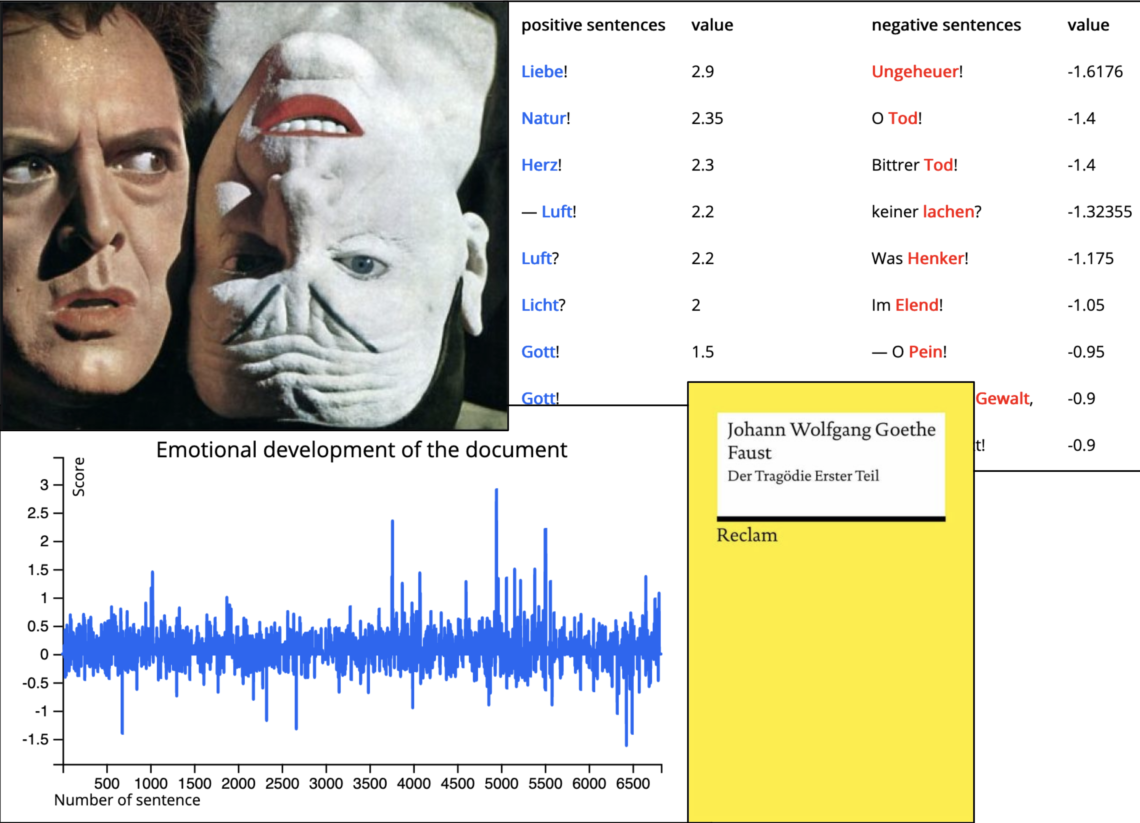
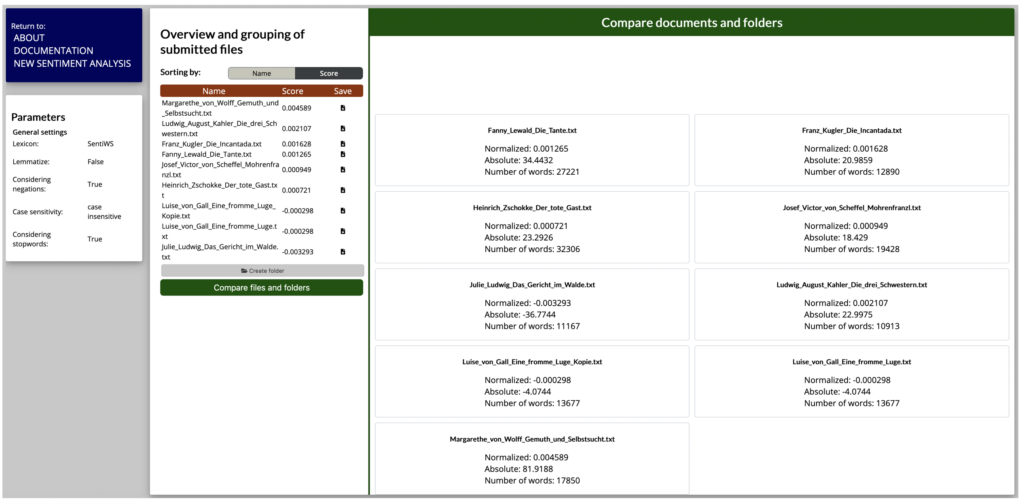
Ein im Frühjahr 2020 publiziertes Tool zur lexikonbasierten Sentimentnalyse ist das an der Uni Regensburg entwickelte Tool SentText (vgl. Abb. 4; eine kurze Toolvorstellung finden Sie bei forTEXT). Einige der Analyseergebnisse aus unserem Kernkorpus möchte ich exemplarisch vorstellen. Das Tool greift in diesem Fall auf das an der Universität Leipzig entwickelte Sentimentwörterbuch SentiWS zurück. Unter den Novellen, die ich hier herangezogen habe, weist “Gemüth und Selbstsucht” den positivsten Sentimentwert auf, den negativsten Wert erzielt “Das Gericht im Walde”.
Im Text-Panel – auf Abb. 5 links – erkennen Sie ihrer Polarität entsprechend farblich hervorgehobene Sentiment-tragenden Wörter und jeweils deren Sentimentwert. Dieser wurde durch den Abgleich mit dem Sentimentwörterbuch bestimmt.

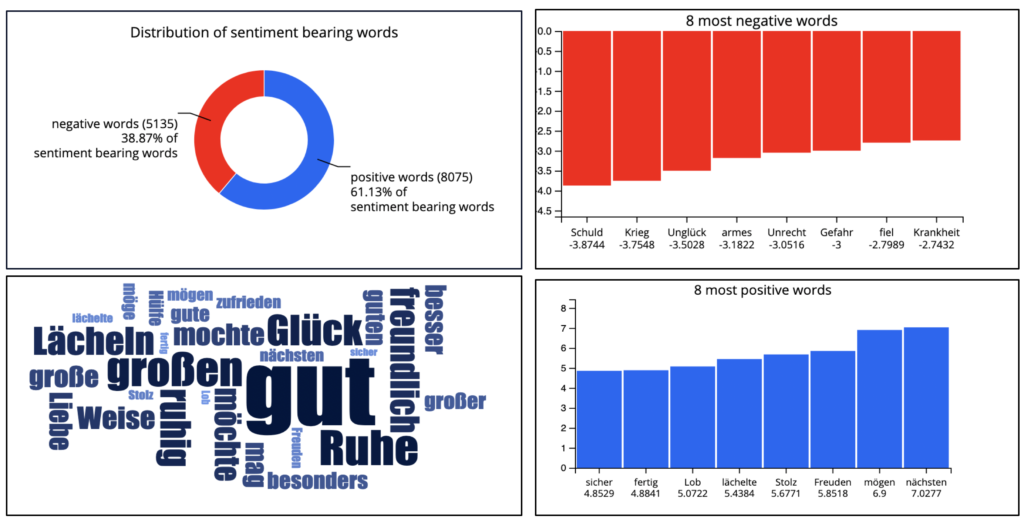
Wie Sie dem Doughnot-Diagramm entnehmen können, überwiegen bei einem Vergleich der Novellen knapp die positiven Sentiment-tragenden Wörter (vgl. Abb. 6). Die Balkendiagramme zeigen: Bei Schuld, Krieg, Unglück, armes, Unrecht, Gefahr, fiel und Krankheit handelt es sich um die 8 besonders negativen (hier rot markierten) Sentimentwörter des untersuchten TeilKorpus’. sicher, fertig, Lob. lächelte oder Freuden sind unter den 8 Wörter mit besonders positiven Sentimentwerten. In der blauen Wordcloud sehen Sie Lexeme wie Glück, oder Liebe in zentralen Positionen, ihnen wurde beim Abgleich mit dem Lexikon ein besonders positiver Sentimentwert zugewiesen.
Wie Sie der kurzen Vorstellung der Analyseergebnisse entnehmen können, lassen sich durch lexikonbasierte Sentimentanalyse unterschiedliche Formen der emotionsbezeichneden Semantik aus literarischen Texten herausfiltern. Diese können auf explizit zum Ausdruck gebrachte Emotionen hinweisen und vor diesem Hintergrund als Emotions-Marker aufgefasst werden.
Die grundlegende Schwäche lexikonbaiserter Sentimentanalysen literarischer Texte, die zu Fehlkalkulationen führen kann, steht im Zusammenhang mit der Domänenspezifik der Sentimentwörterbücher. Diese sind in den meisten Fällen auf das zeitgenössische Vokabular abgestimmt, während literarische Texte gerade ein historischer Sprachstil, eine andere Orthographie oder poetisches Vokabular auszeichnen. Implizite Emotionsinformationen – bspw. Ironie, Metaphern, Hyperbeln oder emotive Wörter (Ausdrücke, die bestimmte Ereignisse bezeichnen, mit denne wir konventionell positive oder negative Emotionen assoziieren) – werden nicht erkannt. Die digitale Literaturanalyse scheint dieser Besonderheit literarischer Texte – dem gehäuften Vorkommen rhetorischer Figuren und impliziten Emotionsmanifestationen – (noch) nicht gerecht werden zu können. Damit kommen wir zur zweiten und bisher deutlich seltener eingesetzten Form der Sentimentanalyse, wobei Verfahren des überwachten maschinellen Lernens eingesetzt werden.
Machine Learning-Ansätze
Hierfür bedarf es zunächst eines Trainingskorpus’, das i. d. R. per Hand erstellt wird (Vgl. Abb. 7). Dieses mit Sentiment- oder Emotionsinformationen angereicherte Trainigskorpus liefert die Trainingsdaten für maschinelles Lernen (vgl. Schmidt, Burghardt, Wolff 2018: 2 und Schmidt, Burghardt und Wolff 2018; Ignatow und Mihalcea 2017, 150). Der große Vorteil dieser Ansätze liegt in der Möglichkeit, dass manuell annotierte Korpora die Spezifik literarischer Texte aufgreifen: “Insgesamt wird bei mangelhaften Ergebnissen mit Sentiment-Lexika der Einsatz von überwachtem maschinellen Lernen empfohlen. Aufgrund der Schwierigkeit der Akquise annotierter Korpora ist dieser jedoch bislang kaum möglich.” (vgl. Schmidt, Burgardt und Wolff 2018: 6). Es fehlt aktuell also vor allem an annotierten Korpora, ansonsten ist die Performanz von ML-Ansätzen im Bereich der Sentimentanalyse meist besser als die der lexikonbaiserten Methoden. Damit kommen wir zu unserem Ansatz, der hermeneutischen Emotionsanalyse mit CATMA.
3. m*w: Hermeneutische Emotionsanalyse mit CATMA
Für die Analyse unseres Korpus’ nutzen wir das Verfahren der digitalen manuellen Annotation und verfolgen somit einen klassischen Close Reading-Ansatz. Hierbei arbeiten wir mit dem Textanalysetool CATMA. Unser Vorgehen umfasst bisher die folgenden vie Arbeitsschritte: 1) Die Textbeschaffung über das DTA, 2) die Textanalyse mit CATMA; hierzu zählen das Projekt- und Tagmanagement, der Annotationsprozess im Close Reading-Modus und der Übergang ins Scalable Reading durch die Query-gestützte Auswertung der Annotationsdaten. Darauf folgt an dritter Stelle die Visualisierung der Annotationsdaten in Form von Emotionsprofilen und 4) deren Interpretation.
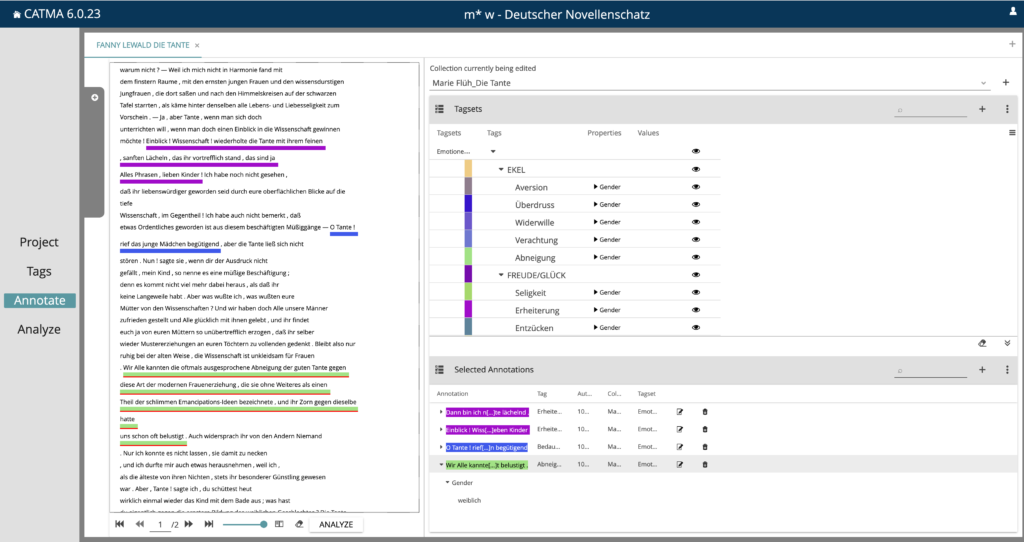
Auf die zentralen Bestandteile der Emotionsanalyse mit CATMA möchte ich etwas genauer eingehen. Ein tragendes Element der Emotionsanalyse stellen Tagsets und Guidelines zu deren Anwendung dar. Tagsets sind Taxonomien, anhand derer die Annotationen erstellt werden. Ein Tagset beinhaltet immer mehrere Tags und ggf. auch Subtags. Ähnlich der Type/Token-Differenz in der Linguistik sind Tags deskriptive Kategorien, wohingegen Annotationen die einzelnen Vorkommnisse dieser Kategorien im Text darstellen. Um möglichst diverse emotionstragende Textstrukturen abbilden zu können, arbeiten wir derzeit mit drei unterschiedlichen Tagsets (vgl. Abb. 8). Während des Annotationsprozesses wird für jede Annotation jeweils die Property „Gender“ als männlich, weiblich oder neutral bestimmt, damit sich annotierte Emotionen schlussendlich einem Geschlecht zugeordnet lassen.

Das obere Tagset – EMOTIONEN_ART – operiert auf der Metaebene. Dieses Tagset zielt darauf ab, Textpassagen herauszufiltern, die eindeutig sowie nicht-eindeutig identifizierbare Emotionsinformationen enthalten. Die Grundlage bilden unterschiedliche strukturorientierte Emotionstheorien; darauf aufbauend wurden konzeptuelle Emotionsfamilien mit mehr oder weniger typischen Mitgliedern entworfen und in dieses Tagset übertragen. Sollte sich ein Textelement nicht ad hoc als Vertreter einer Emotionsfamilie identifiziert lassen, wird ein neuer Subtag erstellt und die entsprechende Annotation der Kategorie “UNGEWISS” zugeordnet. Dieses Vorgehen – die stetige Erweiterung des Tagsets während des Annotationsprozesses – zielt darauf ab, Unsicherheiten und Zweifeln Raum zu geben, die bei der Annotation des per se subjektiven Untersuchungsgegenstands zu erwarten sind.
Das zweite Tagset ist auf der Mesoebene angesiedelt. Es dient der näheren Beschreibung der Emotionen und erfasst deren positive, negative oder neutrale Qualität, die Intensität der Emotionen (gemäßigt oder erregt) und die Dauer des emotionalen Zustands (Zustandsemotion oder Eigenschaftsemotion)
Tagset Nummer 3 ist auf der Mikroebene angesiedelt und dient der linguistischen Beschreibung und Klassifizierung der im Text enthaltenen Emotionsinformationen.
Annotation
Im Textanalysetool sieht das dann folgendermaßen aus (vgl. Abb. 9): Im linken Panel befindet sich der zur Annotation vorgesehene Text, rechts daneben die drei Tagsets zur Analyse. Alle Annotationen werden als Standoff Markups gespeichert, die Textdateien bleiben also unberührt.
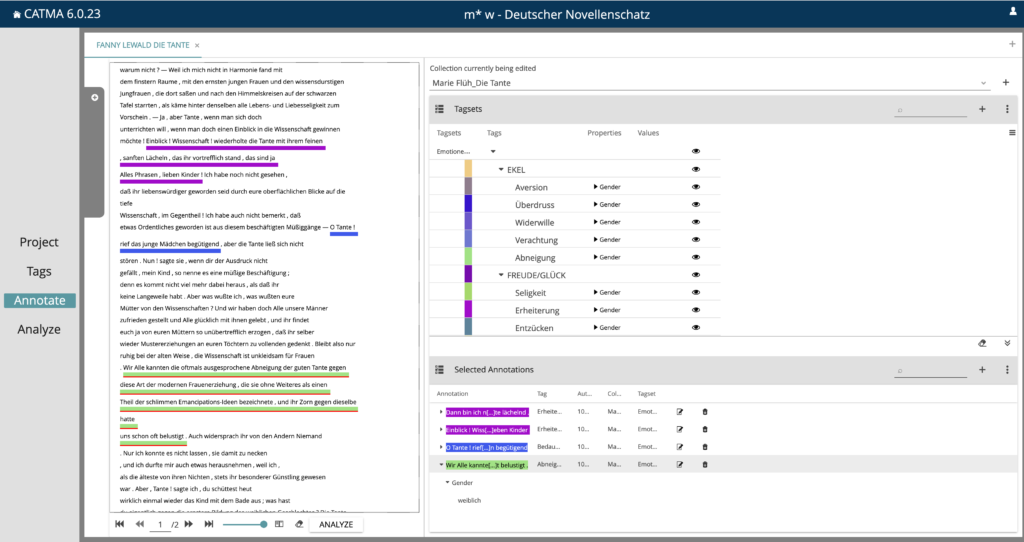
Analyse
Auf die Annotation der Texte folgt die Analyse der Annotationen. Im Analyze-Modul des Tools werden die Annotationsdaten über eine entsprechende Query ausgewertet. Die entsprechende Suchabfrage findet sämtliche Emotionsannotationen, geordnet nach weiblicher, männlicher oder neutraler Value. An dieser Stelle schauen wir im Sinne eines Scalable-Reading-Prozesses also wieder aus der Distanz auf unser Textkorpus und die Verteilung der geschlechtsspezifischen Emotionsinformationen.
Interpretation
Auf Grundlage der Annotationsdaten lassen sich genderspezifische Emotionsprofile entwerfen (vgl. Abb. 10 unten rechts) und anschließend interpretieren. Die Daten werden außerdem tabellarisch und als Diagramme erfasst.
4. Inhaltliches Zwischenfazit
Die Gesamtauswertung aller Annotationen zeigt bisher, dass männliche Figuren häufiger Emotionen zum Ausdruck bringen als weibliche Figuren (vgl. Abb. 10). Diese sind emotional weniger präsent, sie bleiben emotional manchmal sogar beinahe unbeteiligt, obwohl die Heiratsnovellen qua Textsorte Figuren beider Geschlechter enthalten. Männliche Figuren greifen in genau der Hälfte der Fälle auf ein negatives bzw. positives Bewertungssystem zurück. Weibliche Figuren reagieren bisher überwiegend mit negativen Emotionen. Unter rein quantitativer (genderneutraler) Perspektive lassen sich drei Wirkungs- oder Spannungsfelder konstituieren, in denen unterschiedliche Emotionstypen amtieren (1: FREUDE/GLÜCK und FURCHT/ANGST; 2: LIEBE, TRAUER und ZORN; : Problemfällen, ungewisse Emotionstypen und unterschiedliche Formen des Ekels). Eine detaillierte Auswertung der Analyseergebnisse finden sie auf unserem Blog hier.
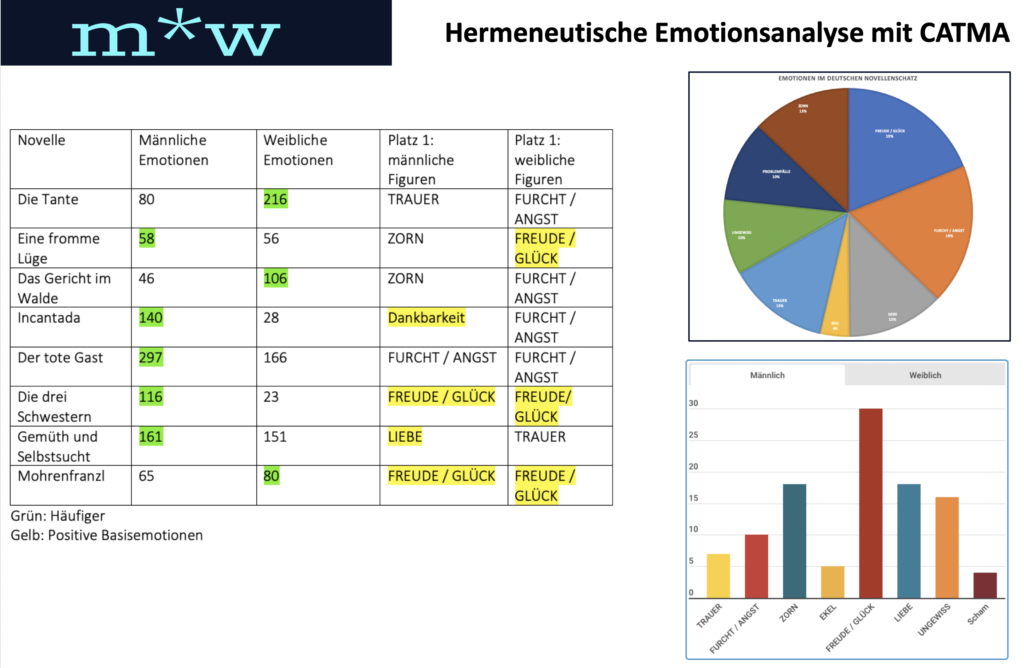
Die bereits herausgearbeiteten unterschiedlichen Emotionsprofile verweisen auf stereotype Darstellungen des Zusammenhangs zwischen Emotion und Geschlecht. Im Kernkorpus werden also prototypische, wiederkehrende emotionale Genderdarstellungen konstruiert, die seitens der Rezipienten wiederum Wirklichkeiten konstruieren dürften, die keinesfalls emotionslos sind. Ob die bisher herausgearbeiteten Profile (“Emotionale Extremreaktion vs. Ausgeglichenheit”, “weibliche Gefühlskälte vs. männliche Emotionalität” und “Emotionaler Overkill”) mit Fortschreiten der noch ausstehenden Analysen um weitere Facetten ergänzt werden oder es bei diesen Kategorien bleibt, wird sich zeigen
5. Methodisches Fazit
- Die Analyse der Annotationsdaten wird durch das Analyze-Modul erheblich erleichtert. Die strukturierte Auswertung und Darstellung der Annotationsdaten, bei der bereits Einzelfallstudien oft an die Grenzen des Darstellbaren geraten, erfährt durch die digitale Arbeitsumgebung in CATMA eine sinnvolle Erweiterung.
- Unser Ansatz kann als Reaktion auf die Probleme bei der Akquise annotierter Korpora für die Weiterentwicklung literaturwissenschaftlicher ML-Sentimentanalyse gesehen werden, wobei sich die Spezifik von Erzähltexten in ihren historischen Kontexten berücksichtigen lässt.
- Darüber hinaus trägt die entwicklung eines korpusspezifischen Glossars dazu bei, die Performanz lexikonbaiserte Analysen – auch über unser Kernkorpus hinaus – zu verbessern.
- Der Vergleich unserer Analyseergebnisse mit den Ergebnissen der lexikonbaiserten Sentimentanalyse mit SentText zeigt übereinstimmende Ergebnisse hinsichtlich der Polarität der Novellen. Die Kombination aus Close- und Scalable Reading geht jedoch deutlich in die Tiefe.
- Wünschenswert wäre eine Projektphase, in der die Novellen kollaborativ annotiert werden, um den Übereinstimmungsgrad von emotionsbezogenen Annotationen bestimmen zu können. Auf diese Weise ließen sich die Annotationsguidelines weiter in Richtung einer “Einführung in die digitale Emotionsanalyse” verfeinern. Technisch wäre das mit CATMA problemlos möglich, es mangelt aktuell eher an Womenpower.
- Gerade die Polyvalenz rhetorischer Figuren und die Tatsache, dass ein und dieselbe sprachliche Struktur ganz unterschiedliche Bedeutungen haben kann, verweisen auf die Notwendigkeit, bei der literaturwissenschaftlichen Emotionsanalyse auch Unsicherheiten im Annotationsprozess annotieren und irgendwie abbilden zu können. Durch die Vergabe entsprechender Properties und Values (Grad der Ungewissheit beim Annotieren) ließe sich mit CATMA auch in Richtung einer “Modellierung von Vagheit” arbeiten, dieser Ansatz steht aktuell im “Gegensatz zu den bisher vorherrschenden Ansätzen, bei denen eine eindeutige Polarität bestimmt werden soll (vgl. Schmidt, Burghardt und Wolff 2018: 6).
6. Ausblick: Den Hermeneutischen Zirkel schließen
Ich schließe den Beitrag mit einem Ausblick auf zukünftige Arbeitspakete und offene Fragen.
Ein noch ausstehendes Arbeitspaket beinhaltet die Vernetzung beider m*w-Schwerpunktbereiche, also die Beantwortung der Frage, auf welche Art und Weise sich Close- und Distant Reading-Ansätze gewinnbringend miteinander kombinieren lassen (vgl. Abb. 11).
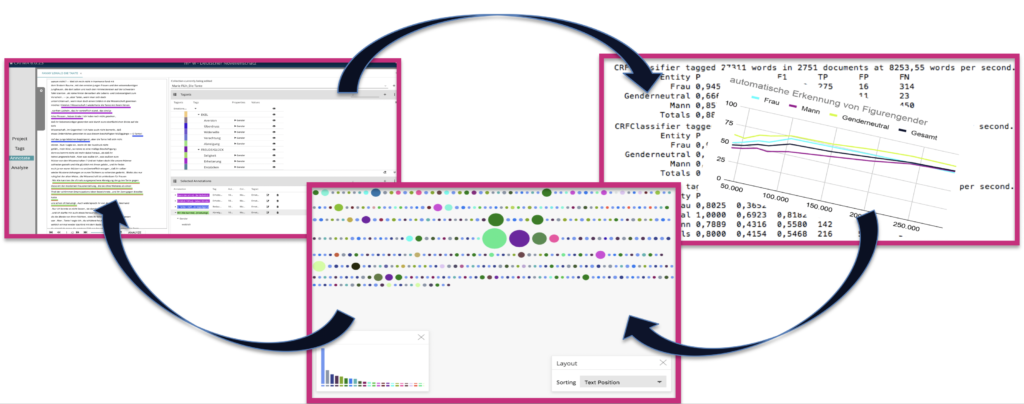
Methodische Verknüpfung: Manuelle Emotionsanalyse und Named Entity Recognition
Das NER-Modell ermöglicht es, mit der Analyse bzw. Interpretation direkt am Epizentrum des Forschungsinteresses anzusetzen. Das trainierte Modell findet genderstereotype Figurendarstellungen in novellistischen Texten bzw. großen Textkorpora. Durch die Implementierung in CATMA lassen sich diese Gender-Marker im übrigen Korpus automatisiert herausfiltern. Darauf aufbauend kann das semantische Umfeld hinsichtlich enthaltener Emotionsinformationen annotiert und analysiert werden. Distant Reading unterstützt also den Einstieg in den hermeneutischen Zirkel, zu dem wir den Zugang – erneut Emil Staigers Vorstellungen folgend – erst finden müssen. Gleiches gilt für die Verzahnung von lexikonbasierter Sentimentnalyse mit SentText und der Close Reading-Emotionsanalyse mit CATMA.
SentText eigenet sich, um in den Novellen stimmungsgeladene Lexeme zu lokalisieren. Ähnlich wie die Kopplung an das NER-Modell können diese als Emotions-Marker genutzt werden, um das semantische Umfeld hinsichtlich etwaiger Figurenreferenzen und genderbezogenen Emotionsinformationen genauer zu untersuchen.
Inhaltliche Verknüpfung: Gendermodell und Emotionsprofile
Der Rückbezug der Emotionsprofile zum auf kulturwissenschaftlichen Analysen basierenden und mittels NER erweiterten Gendermodell führt zu einer emotionsbezogenen Ausdifferenzierung etablierter Gender Stereotype in der Literatur. Darauf aufbauend lässt sich diskutieren, welche Wirklichkeiten und erzählte Welten durch die emotionale Ausstaffierung einer stereotypen Geschlechterrolle konstruiert werden können. Welche Komponenten enthält das Emotionsprofil der literarischen Figuren der Mutter, der Ehefrau oder der Tochter? Welche Emotionen bestimmen das Wertkonzept der literarischen Vater-, Sohn-, oder Freier-Figur? Dieser Abgleich steht noch aus (vgl. Abb. 12).

Ich schließen mit dem Ausblick, dass durch die Kombination der digitalen textanalytischen Verfahren zur Herausarbeitung emotiver Bedeutungskomponenten und Gender-Stereotypen künstlich konstruierte Wirklichkeiten als ebensolche – als Konstrukte – sichtbar gemacht werden können. Darauf aufbauend lässt sich die Performanz zwischen Gender, Emotionen und Macht hinterfragen sowie starre, persistente Vorstellungen über den Zusammenhang von Emotion und Gender neu verhandeln.
Referenzen
Alfes, Henrike F. (1995): Literatur und Gefühl: Emotionale Aspekte literarischen Schreibens und Lesens. Opladen: Westdeutscher Verlag.
Anz, Thomas (2007): „Kulturtechniken der Emotionalisierung. Beobachtungen, Reflexionen und Vorschläge zur literaturwissenschaftlichen Gefühlsforschung.“ In: Karl Eibl Katja Mellmann und Rüdiger Zymner (Hrsg.): Im Rücken der Kulturen. In: Karl Eibl, Manfred Engel, Rüdiger Zymner (Hrsg): Poetogenesis. Studien und Texte zur empirischen Anthropologie der Literatur. Band 5. Paderborn: mentis, 207–241.
Flüh, Marie: „1. Analyseergebnisse: Emotionen und Gender im Deutschen Novellenschatz“. In: m*w, Juni 19, 2020, https://msternchenw.de/1-analyseergebnisse-emotionen-und-gender-im-deutschen-novellenschatz/, [Zugriff am: 3. Juli, 2020].
Ignatow, GabrielGabriel Gabriel ist ein Roman von George Sand aus dem Jahr 1839. Die Protagonistenfigur Gabriel/le wächst als Enkel und Alleinerbe des Fürsten von Bramante, abgeschieden von der Gesellschaft, auf. Erst als Jugendlicher erfährt er, dass er eine Frau ist und muss das Geheimnis weiter bewahren, damit das Vermögen nicht auf seinen Cousin Astolphe fällt. Als sie aber auf Adolphe trifft, entscheidet Gabriel/le sich für Doppelleben: Auf dem Land lebt sie als Frau mit Adolphe zusammen, in der Stadt lebt sie als Mann. Das biologische Geschlecht wird für unterschiedliche gesellschaftliche Kontexte angepasst. Diversität wird in dem Roman durch die Auseinandersetzung mit unterschiedlichen Geschlechteridentitäten umgesetzt. und Rada Mihalcea (2017): Text Mining. A guidebook for the Social Sciences. Los Angeles (u. a.): SAGE.
Kalwa, Nina (2015): „Emotionen in literarischen Texten. Eine sprachwissenschaftliche Analyse.“ In: Jochen A. Bähr, Jana-Katharina Mende und Pamela Stehen (Hrsg.): Literaturlinguistik. Philologische Brückenschläge. Frankfurt am Main: Peter Lang, 255–275.
Kim, Evgeny und Roman Klinger (2019): „A Survey on Sentiment and Emotion Analysis for Computational Literary Studies.“ In: Zeitschrift für digitale Geisteswissenschaften Wolfenbüttel 2019. URL: http://www.zfdg.de/2019_008, [Zugriff am: 28. Juni 2020].
Liu, Bing (2015): Sentiment Analysis: Mining Opinions, Sentiments and Emotions. Cambridge: University Press.
Meister, Jan Christoph, Jan Horstmann, Marco Petris, Janina Jacke, ChristianChristian Christian ist eine anonym publizierte Kurzgeschichte aus dem Jahr 1954. Der namenlose Protagonist sitzt im Flugzeug und reflektiert eine Begegnung mit einer zweiten Figur, Christian. Dabei gerät er ins Schwärmen und fragt sich, ob nur er die Zuneigung gespürt hat oder die spontane Anziehung beidseitig war. . Glücklich erfüllt von den Kleinigkeiten dieser Begegnung träumt er vor sich hin. Die queere Sehnsucht, die den Gedankengang des Protagonisten bestimmen, ist der zentrale Aspekt dieser Kurzgeschichte. Bruck, Mareike Schumacher und Marie Flüh (2019): CATMA 6.0.0 (Version 6.0.0). Zenodo. DOI: 10.5281/zenodo.3523228
Mellmann, Katja (2007): „Emotionalität und Verhalten. Eine literaturpsychologische Kritik des Werther-Mythos.“ In: Thomas Anz und Martin Huber (Hrsg.): Mitteilungen des Deutschen Germanistenverbandes. Literatur und Emotionen. Heft 3/2007. Bielefeld: Aisthesis, 346–328.
Mellmann, Katja (2010): „Gefühlsübertragung? Zur Psychologie emotionaler Textwirkungen.“ In: Kasten, Ingrid (Hrsg.): Machtvolle Gefühle. Berlin/New York: De Gruyter, 107–119.
Mellmann, Katja (2016): “Empirische Emotionsforschung.“ In: Cornelia Zumbusch und Martin von Koppenfels. (Hrsg.): Handbuch Literatur & Emotionen. Berlin/Boston: De Gruyter, 158–179.
Ortner, Heike (2014): Text und Emotionen: Theorie, Methode und Anwendungsbeispiele emotionslinguistischer Textanalyse. Tübingen: Narr.
Poppe, Sandra (2012): „Emotionsvermittlung und Emotionalisierung in Literatur und Film – eine Einleitung.“ In: Sandra Poppe (Hrsg.): Emotionen in Literatur und Film. Königshausen & Neumann: Würzburg, 9 – 31. In: Oliver Jahraus und Stefan Neuhaus: Film – Medium – Diskurs Band 36.
Schmidt, Thomas, Manuel Burgardt und Christian Wolff (2018): „Herausforderungen für Sentiment Analysis bei literarischen Texten”. In: Manuel Burghardt und Claudia Müller-Birn (Hrsg): NF-DH 2018 – Workshopband, 25. Sept. 2018. URL: https://doi.org/10.18420/infdh2018-16, [Zugriff am 28. Juni 2020].
Schmidt, Thomas, Manuel Burghardt und Katrin Dennerlein (2018a): „,Kann man denn auch nicht lachend sehr ernsthaft sein?‘ – Zum Einsatz von Sentiment Analyse-Verfahren für die quantitative Untersuchung von Lessings Dramen”. In: Book of Abstracts, DHd 2018. https://epub.uni-regensburg.de/37579/1/Self-Archiving-Version_DHd-2018.pdf(link is external), [Zugriff: 9. September 2019].
Schonlau, Anja (2017): Emotionen im Dramentext. Eine methodologische Grundlegung mit exemplarischer Analyse zu Neid und Intrige 1750 – 1800. Berlin/Boston: De Gruyter.
Schwarz-Friesel, Monika (2017): “Das Emotionspotenzial literarischer Texte”. In: Anne Betten, Ulla Fix und Berbeli Wanning (Hrsg): Handbuch Sprache in der Literatur. Berlin, Boston: De Gruyter, 351–370.
Staiger, Emil (1955): Die Kunst der Interpretation. Zürich: Antlantis.
SentText: Entwickelt von Johanna Dangel und Thomas Schmidt. URL: http://thomasschmidtur.pythonanywhere.com, [Zugriff am 28. Juni 2020].
Winko, Simone (1990): Kodierte Gefühle. Zu einer Poetik der Emotionen in lyrischen und poetologischen Texten um 1900. Berlin: Erich Schmidt.
Zumbusch, Cornelia und Martin von Koppenfels (2016): „Einleitung.“ In: dies. (Hrsg.): Handbuch Literatur & Emotionen. Berlin/Boston: De Gruyter.


Das könnte dich auch interessieren

Tage im Leben von …
Fundvogel

Ein Kommentar
Pingback: