Queere (auto)biographische Texte im Diversitäts-Korpus
Das Diversitätskorpus beinhaltet Erzähltexte aller Art, darunter auch einige Texte, die nicht rein fiktional sind. Die Rede ist von (auto)biographischen Texten, die in DisKo einen kleinen Teil ausmachen. Aber was zeichnet eine Biographie aus und wie steht es um queere…
Fundvogel
Der Roman Fundvogel von Hanns Heinz Ewers bietet aus heutiger Sicht – man kann es nicht anders sagen – eine äußerst merkwürdige Lektüre. Die 1928 erschienene Geschichte einer TransitionTransition Als Transition wird ein Prozess beschrieben, den eine trans* Person durchläuft,…
Sichtbarmachung non-binärer Genderdarstellungen in literarischen Texten (SiNG)
Nicht-binäre Genderdarstellungen sind gar nicht so ungewöhnlich, sondern kommen in zahlreichen literarischen Texten vor. Aber in welchen eigentlich genau? Und welche Figuren betrifft diese Darstellung? In diesem Blogbeitrag möchten wir von einem Teilprojekt berichten, das seit einiger Zeit zu DisKo…
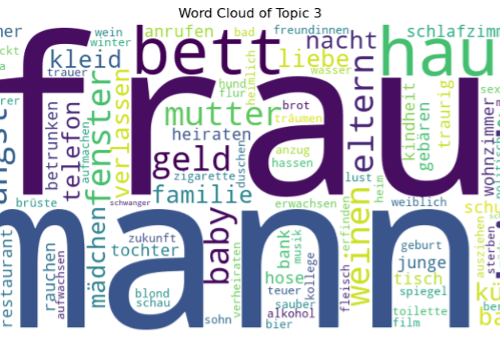
Von Angst bis Naturmystik: Die Themen im DisKo analysiert
Ein Beitrag von: Verena Schmitt & Lukas Kagerer Als Literaturwissenschaftler*innen arbeiten wir traditionell vor allem an einzelnen Werken, analysieren Motive oder stellen vergleichende Literaturanalysen zwischen Romanen an. Diese Arbeit ist in jedem Fall lohnend, allerdings auch sehr zeitintensiv. Für ein…
Allein – oder zu zweit(?) – gegen den Rest einer kleinen Welt: Oskar Panizzas “Ein skandalöser Fall”
Die Erzählung Ein skandalöser Fall von Oskar Panizza erlangte wohl vor allem dadurch Aufmerksamkeit, dass Michel Foucault sie lange nach ihrer Erstveröffentlichung im Jahr 1893 in sein Buch Über Hermaphroditismus aufnahm. Panizza verarbeitet in dieser Erzählung einen frühen, in der…
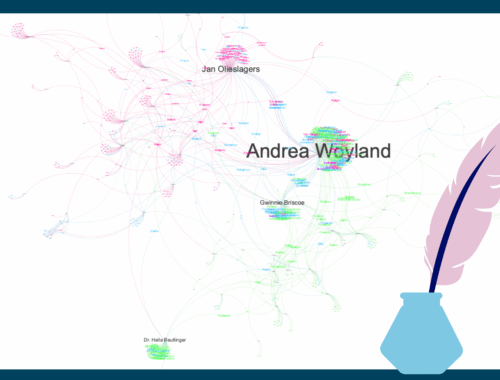
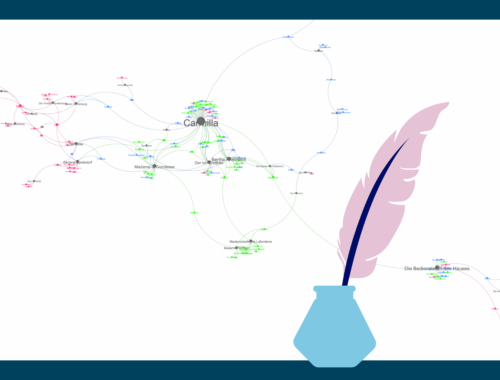
Sheridan le Fanus “Carmilla”: Weiblicher Vampir sucht weibliche Opfer
Nachdem wir euch letzten Monat mit Balzacs Sarrasine einen richtigen Klassiker der ungewöhnlichen Gender-Darstellungen vorgestellt haben, präsentieren wir diese Woche einen weniger bekannten Text. Nach diesem irischen Kleinod der Vampirliteratur mussten wir regelrecht eine Zeit lang suchen, bevor wir es…
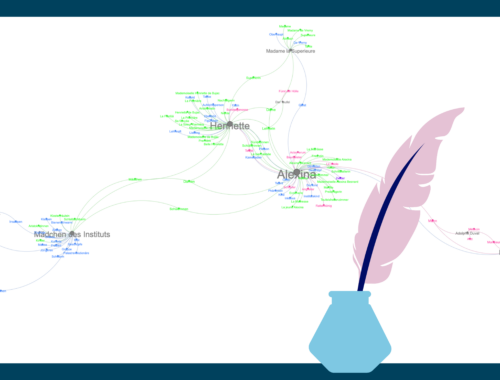
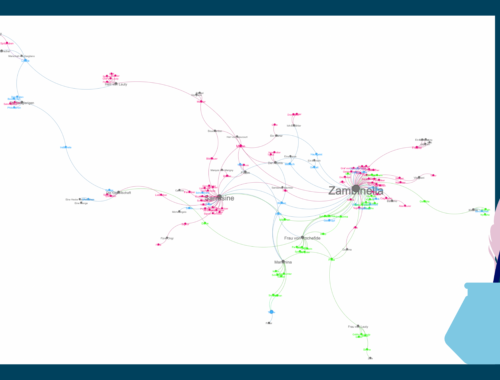
Literarischer Klassiker der ungewöhnlichen Gender-Darstellungen: Balzacs Sarrasine
Wenn wir gendersensible Perspektiven in die (digitalen) Literaturwissenschaften und auch in den Literaturunterricht einbringen wollen, brauchen wir dafür vor allem eines: Texte, in denen ungewöhnliche Darstellungen von Gender eine Rolle spielen. Für unser Diversitätskorpus DisKo sammeln wir solche Texte. Einen…
Diversität der Gender-Darstellungen in literarischen Texten
In unserem Korpus-Projekt DisKo sammeln wir Titel von literarischen Texten, in denen ungewöhnliche Gender-Darstellungen vorkommen. Über 100 Texte haben wir schon auf unserer Liste verzeichnet. Aber wie genau sehen ungewöhnliche Darstellungen von Gender aus? In was für Geschichten kommen sie…
Empirische Literaturwissenschaft meets m*w
Team m*w war mal wieder on Tour. Dieses Mal haben wir einen Ausflug ins süditalienische Monopoli gemacht, um unsere Arbeit einer Gruppe empirisch arbeitender Literaturwissenschaftler*innen, der IGEL-Society, vorzustellen. Bei exquisitem Kaffee und luftigem veganen Kuchen (na gut, das ein oder…
DisKo meets Citizens Humanities
Auf der diesjährigen Tagung des Verbands Digital Humanities im deutschsprachigen Raum (DHd) drehte sich alles um das Motto Open Humanities Open Culture. Viele spannende Projekte und Forschungsergebnisse wurden vorgestellt, wie z.B. auch unser Diversitäts-Korpus (DisKo). Wir haben Einblicke in unseren…