Sichtbarmachung non-binärer Genderdarstellungen in literarischen Texten (SiNG)
Nicht-binäre Genderdarstellungen sind gar nicht so ungewöhnlich, sondern kommen in zahlreichen literarischen Texten vor. Aber in welchen eigentlich genau? Und welche Figuren betrifft diese Darstellung? In diesem Blogbeitrag möchten wir von einem Teilprojekt berichten, das seit einiger Zeit zu DisKo…
Coding Gender – Decoding Literature: DisKo auf der „Digital Total“
Im Oktober 2023 haben sich auf der vom House of Computing und Data Science (HCDS) veranstalteten Konferenz “Digital Total” unterschiedliche Projekte, die in irgendeiner Weise mit Computing und Data Science zu tun haben, vorgestellt. Ob Virologie, Nanotechnologie, Klimaforschung, Linguistik oder…
Teilkorpus ‘Wiener Moderne’: Texte aus der Zeit der ‘Wiener Moderne’, in denen Gender-Diversität eine Rolle spielt oder: ein Weg zum ‘Traumkorpus’
Wie komme ich zu einem Textkorpus, das sich für eine Fallstudie mit DH-Fokus eignet? Neben der Zusammenarbeit mit Bibliotheken und euch führt der Weg zum ‘Traumkorpus’ auch bei uns über die Recherche in literaturwissenschaftlicher Sekundärliteratur. Wie ein Teilkorpus mit potenziell…
Projekt DisKo: Aufbau eines Diversitäts-Korpus (DisKo) als Grundlage für die algorithmische Textanalyse
In der letzten Zeit haben wir in verschiedenen Fallstudien untersucht, wie Genderrollen in unterschiedlichen Genres dargestellt werden und neue Einblicke in die Verteilung stereotyper Genderrollen (und deren Zusammenhang zu Emotionen) gewonnen. Dem m*w-Ansatz folgend haben wir dabei unseren Machine-Learning-Algorithmus zur…
Tage im Leben von …
Emotionen bestimmen Denken, Handeln und auch Schreiben. Aber wie beschrieben Frauen ihre Emotionen und wie fassten Männer sie in Worte? Noch – oder gerade heute – gilt: Wer es ernst meint, tippt keine E-Mail, sondern greift zu Stift und Papier…
Typologisierungsversuche zur Emotionsanalyse
Neben der feschen Frisur vereint diese vier Herren (v. l. n. r.: Aristoteles, Réne Descartes, Baruch de Spinoza, David Hume) ein ausgeprägtes Interesse an Fragen nach Mechanismen und Strukturen, die die menschliche Existenz beeinflussen. Daraus ging u. a. eine intensive…
Sprache und Emotionen in literarischen Texten
In diesem Blogbeitrag, der den zweiten Teil des Vortrags „Von Nebenbefunden und Methodenadaptionen in den Digital Humanities am Beispiel von m*w“ darstellt, werde ich näher auf den zweiten Schwerpunkt unseres Projekts eingehen. Wir möchten herausfinden, welche genderstereotypen Emotionsinformationen in novellistischen…
Von Nebenbefunden und Methodenadaptionen in den Digital Humanities am Beispiel von m*w
Wie der/die aufmerksame Leser*in weiß, untersuchen wir seit Sommer 2019 Gendersterotype und -bewertungen (in Form von Emotionen) in literarischen Texten. Im Rahmen eines Kolloquiums an der Berlin Brandenburgischen Akademie der Wissenschaften haben wir den aktuellen Stand unserer beider methodischen Schwerpunkte…
1. Analyseergebnisse: Emotionen und Gender im Deutschen Novellenschatz
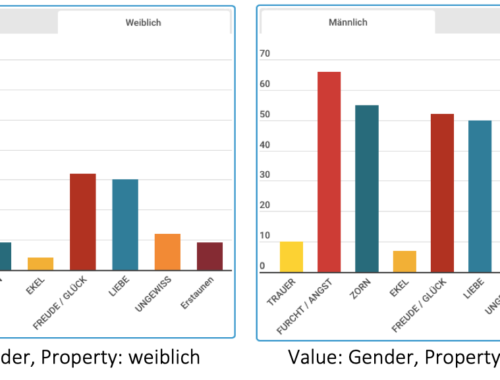
Die Analyse des ersten Drittels unseres Korpus ist geschafft. In diesem Beitrag ziehen wir eine vorsichtige Zwischenbilanz hinsichtlich einer genderstereotypen Verteilung der im Deutschen Novellenschatz verborgenen Emotionsinformationen. Zur Erinnerung: Wir möchten u. a. herausfinden, welche Emotionen männliche, weibliche oder diverse…
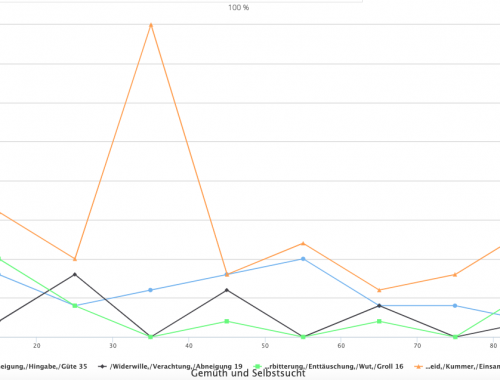
Emotionsinformationen analysieren: 3. Erste Ergebnisse – Gemüth und Selbstsucht (1787) von Margarethe von Wolff
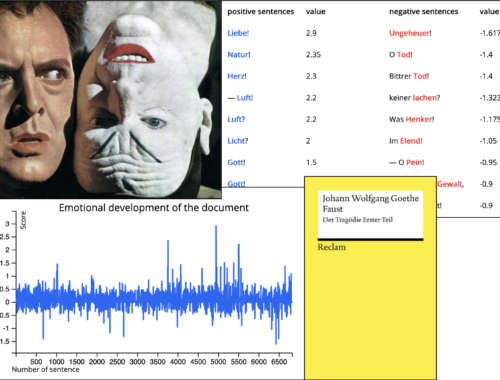
Für die Auswertung der Annotationen, die die Art der Emotion betreffen, haben wir für jedes Mitglied einer Emotionsfamilie eine Query verwendet, die die Anzahl der Tags anzeigt (Text ID 76, 20.954 Wörter, Annotation Collection Marie_Text 76). Im Text sehen die…