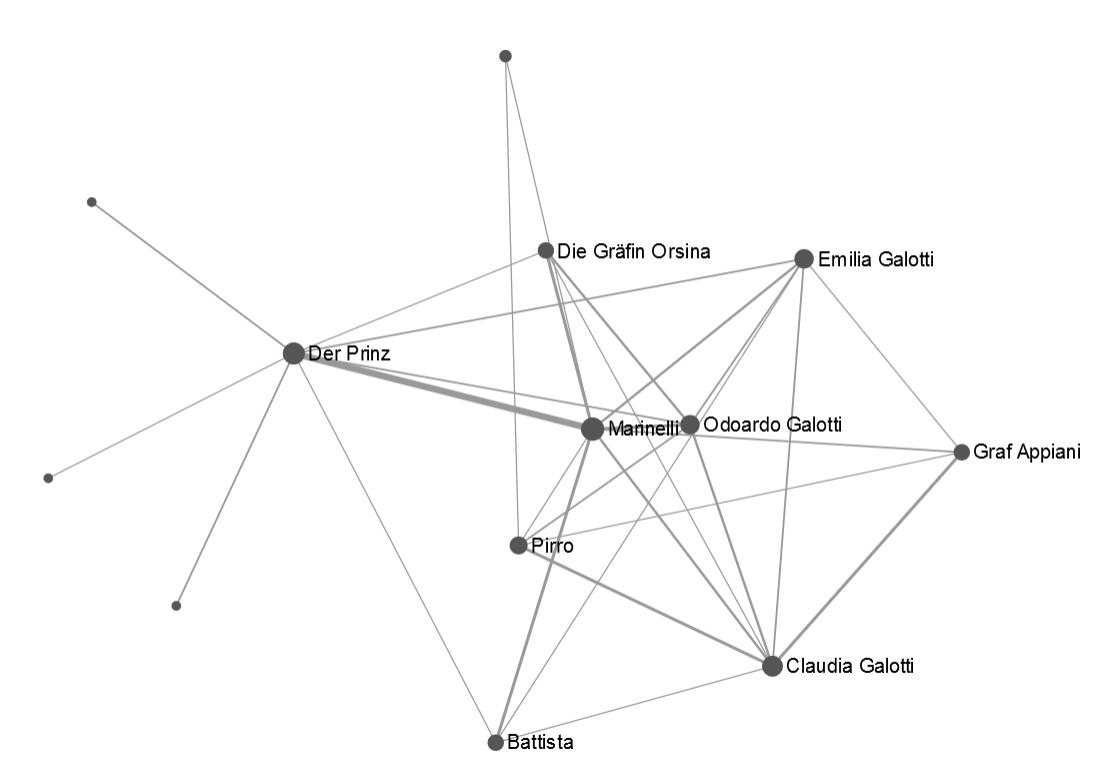
Netzwerkanalyse und warum sie erst in Verbindung mit anderen Methoden der digitalen Textanalyse ihr volles Potential entfaltet
Ein Beitrag von Lea Röseler zur Netzwerkanalyse
Netzwerkanalyse – Wenn A mit B spricht, aber nicht mit C
Der wohl wichtigste Bestandteil literarischer Werke sind sicherlich die Figuren. Durch ihre Handlungen und Interaktionen bringen sie die Geschichte voran. Doch wie kann man Figuren und ihre Beziehungen zueinander darstellen? Wie kann man zeigen, dass bestimmte Figuren häufig zusammen auftreten, jedoch nicht mit anderen? Oder dass A häufig mit B über C spricht, jedoch nie mit C persönlich interagiert? Eine gute Möglichkeit hierfür sind Netzwerkanalysen, mit denen sowohl gemeinsames Auftreten als auch verschiedene Beziehungen der Figuren zueinander dargestellt werden können (Schumacher, 2019). Hierbei zeigen Linien oder Pfeile in unterschiedlicher Stärke Verbindungen zwischen den Figuren an. Doch natürlich geschieht das nicht von allein, sondern es wird gewisser Input benötigt. Eine Liste aller Figuren für jede Szene? Eine einfache und schnelle Lösung. Doch was, wenn man mehr darstellen möchte als lediglich die Kopräsenz verschiedener Figuren im Verlauf eines Werkes?
Annotation – Vorarbeit ist die halbe Miete
Ein hilfreiches Werkzeug zur Visualisierung der Figurenkonstellation in einem Werk kann eine Netzwerkanalyse sein. Jedoch ist diese nur so gut, wie die ihr zugrunde liegenden Daten. Wie bei jeder Untersuchung ist auch hier die Fragestellung von großer Bedeutung. Was soll mit dem Netzwerk dargestellt werden? Das gemeinsame Auftreten von Figuren? Oder sollen Beziehungen von Figuren zueinander visualisiert werden, wie z.B. Machtverhältnisse oder Liebesbeziehungen? Es reicht jedoch nicht aus, dem Tool eine Liste aller vorkommenden Figuren zu geben und dann erstellt es auf wundersame Weise ein akkurates Netzwerk, welches die komplette Handlung des Werkes repräsentiert. Stattdessen müssen dem Tool, je nachdem, was das Netzwerk zeigen soll, entsprechende Daten gegeben werden.
Wenn wir beispielsweise untersuchen möchten, ob die zentralen Figuren eines Dramas auch die Figuren sind, über die am meisten geredet wird, benötigen wir andere Daten, als wenn wir zeigen möchten, welche Figuren häufig am gleichen Ort auftauchen. Selbstverständlich können wir diese Daten direkt in das Netzwerkanalyse-Tool eingeben, jedoch ist dies aufwendig und für nachträgliche Änderungen ungeeignet. Stattdessen kann eine mehrstufige Annotation im Vorfeld die Arbeit nicht nur erleichtern, sondern auch das Netzwerk differenzierter ausfallen lassen. Die Annotation kann hierbei entweder manuell, automatisch oder halb-automatisch durchgeführt werden, wobei eine automatische Annotation zumeist recht fehleranfällig ist, manuelles Annotieren hingegen viel Zeit in Anspruch nimmt.
Named Entity Recognition – Ein Netzwerk will bevölkert sein
Für eine Netzwerkanalyse besonders relevant sind natürlich die Figuren eines Werkes. Es kann deshalb hilfreich sein, diese im Vorfeld zu identifizieren und deren Auftreten im Verlauf der Geschichte zu annotieren. Eine Named Entity Recognition kann hierbei Personen, Organisationen und Orte unterscheiden, wobei je nachdem, wie der Algorithmus trainiert wurde, auch andere Parameter berücksichtigt werden können, beispielsweise das Geschlecht einer Person. Damit erhalten wir zwar keine differenzierte Liste der einzelnen Figuren, jedoch erfasst eine erfolgreiche Named Entity Recognition alle Vorkommen der spezifizierten Instanzen (Personen, Organisationen, Orte), in Fällen, in denen mithilfe von Eigennamen oder Nominalphrasen auf diese verwiesen wird.
Aufgrund der abgesetzten Bühnenanweisungen und der hervorgehobenen Figurennamen vor wörtlicher Rede ist eine automatische Erkennung von Figuren- und Ortsbezeichnungen in Dramen einfacher als in Romanen. Aus diesem Grund gibt es auch bereits zahlreiche Netzwerkanalysen zu Figurenkonstellationen in Dramen (Fischer, Trilcke and Orekhov, 2018). In Romanen hingegen sollte für eine zuverlässige Named Entity Recognition und eine darauf aufbauende Netzwerkanalyse zumindest eine halb-automatische Annotation durchgeführt werden, in der die automatisch annotierten Daten noch einmal manuell überprüft und gegebenenfalls verbessert werden.
Koreferenz – Wenn Pronomen ins Gewicht fallen
Nachdem wir die Named Entity Recognition angewendet haben, haben wir eine Liste von Personen, Organisationen und Orten, die in dem von uns untersuchten Werk vorkommen. Je nachdem, wie gut unser Algorithmus trainiert ist oder ob wir manuell annotiert haben, haben wir hierbei nicht nur konkrete Namen, sondern auch Nominalphrasen erfasst, die auf diese verweisen. Dies ist ein guter Anfang, doch längst nicht alle Verweise auf Figuren und Orte erfolgen mithilfe von Eigennamen oder Nominalphrasen. Tatsächlich überwiegt in den meisten Fällen die Anzahl der referentiellen Pronomen.
In einem Satz wie Marie geht jeden Tag zur Uni und redet dort mit ihren Freunden, welche sie sehr gern hat würden durch die Named Entity Recognition nur Marie und Uni und möglicherweise Freunden gefunden werden. Doch was ist mit den Pronomen ihren, welche und sie? Um diese zu erfassen, kann eine Koreferenz-Annotation durchgeführt werden, in welcher nicht nur Eigennamen und Nominalphrasen, sondern auch Pronomen erfasst werden. Diese kann ebenso wie die Named Entity Recognition automatisch erfolgen, aufgrund der Ambiguität vieler Pronomen ist eine manuelle Annotation jedoch zuverlässiger.
Viele Methoden, ein Ergebnis – Teamwork, das sich auszahlt?
Jetzt kann man sich natürlich fragen: Warum das alles? Ist dieser ganze Aufwand wirklich notwendig? Warum sollte ich mindestens drei verschiedene Tools verwenden, um zu einem Ergebnis zu kommen, dass ich auch einfacher haben könnte? Und überhaupt, ist der ganze Prozess nicht unglaublich fehleranfällig? Was ist, wenn bei der Named Entity Recognition eine Figur fehlerhaft als Ort erkannt wurde, dieser Fehler jedoch nicht entdeckt wurde und sich damit durch alle weiteren Schritte zieht? Ein Fehler zu Beginn der Annotation kann somit das gesamte Ergebnis beeinflussen und verfälschen. Eine automatische Annotation birgt immer Risiken und diese sollten stets abgewogen werden. Doch eine manuelle oder zumindest halb-automatische Annotation auf verschiedenen Ebenen bringt viele Vorteile für die Netzwerkanalyse. Selbstverständlich muss der Aufwand für das jeweils gewünschte Ergebnis angemessen sein.
Wenn meine Fragestellung kein komplexes Netzwerk fordert und das dargestellte Werk und dessen Figuren nicht sonderlich umfangreich sind, kann auf die ganzen hier vorgestellten Schritte verzichtet werden. Jedoch ermöglicht eine umfangreiche Annotation auf verschiedenen Ebenen eine komplexere und detailliertere Darstellung. Mithilfe der Named Entity Recognition können beispielsweise Orte mit in die Analyse einbezogen werden und eine Koreferenz-annotation verhindert, dass lediglich Eigennamen und Nominalphrasen als Vorkommen von Figuren gewertet werden. Dies könnte zu verzerrten und sogar fehlerhaften Darstellungen führen, in denen das Vorkommen bestimmter Figuren aufgrund der nicht-beachteten Pronomen größere bzw. weniger große Bedeutung zukommt. Wer also das Potential der Netzwerkanalyse voll ausschöpfen möchte und ein komplexes und aussagekräftiges Netzwerk erstellen möchte, der sollte durchaus eine Kombination verschiedener Tools und Methoden in Betracht ziehen.
Diesen Artikel zitieren: Lea Röseler: „Netzwerkanalyse und warum sie erst in Verbindung mit anderen Methoden der digitalen Textanalyse ihr volles Potential entfaltet.“?“. In: m*w, Februar 4, 2020, http://msternchenw.de/netzwerkanalyse-und-warum-sie-erst-in-verbindung-mit-anderen-methoden-der-digitalen-textanalyse-ihr-volles-potential-entfaltet/.
Referenzen
- Fischer, F., Trilcke, P. and Orekhov, B. (2018) Lessing: Emilia Galotti, DraCor. Available at: https://dracor.org/ger/lessing-emilia-galotti (Accessed: 28 January 2020).
- Schumacher, M. (2019) Netzwerkanalyse, forTEXT. Available at: https://fortext.net/routinen/methoden/netzwerkanalyse (Accessed: 28 January 2020).


Das könnte dich auch interessieren

Automatische Erkennung von Figuren-Gender – das erste Modell
Von Angst bis Naturmystik: Die Themen im DisKo analysiert
