Ziel erreicht, doch wir machen weiter! m*w-Jahresrückblick 2024
Im Jahr 2024 war es etwas ruhiger hier auf unserer m*w-Webseite. Das lag natürlich auch daran, dass wir uns beruflich immer weiter entwickeln und für m*w dabei nicht immer die Zeit-Ressourcen bleiben, die wir dem Projekt gerne widmen würden. Marie hat im vergangenen Jahr zwar weiter an der Universität Hamburg gearbeitet, aber nicht mehr im Projekt Dehmel-digital, sondern in CompAnno, einem neuen Projekt mit neuen Herausforderungen. Ich (Mareike) habe im April angefangen, die Professur für Digital Humanities an der Universität Stuttgart zu vertreten, was auch ein neues Umfeld und Einiges an Umorganisation mit sich brachte. Selbst wenn wir nicht immer dazu gekommen sind, auf dieser Webseite darüber zu schreiben, haben wir aber im Hintergrund weiter zu ungewöhnlichen Gender-Darstellungen geforscht. Wir haben unsere Diversitätskorpus-Liste mit euren Einreichungen kontinuierlich ergänzt und dabei Dank euch unser Ziel von 100 Titeln erreicht. Vielen, vielen Dank dafür! Viele der Titel auf unserer Liste haben wir mit tiefergehenden Informationen hinterlegt. Wir haben dazu noch eine zweite Sammlung mit älteren Texten begonnen. Und wir haben kontinuierlich Texte annotiert (wofür wir unser Team vergrößert haben). Worauf du dich jetzt in 2025 aufgrund der neuen Datenlage freuen kannst, das erfährst du am Ende dieses Posts.
DisKo – das Diversitätskorpus verzeichnet nun mehr als 100 Titel
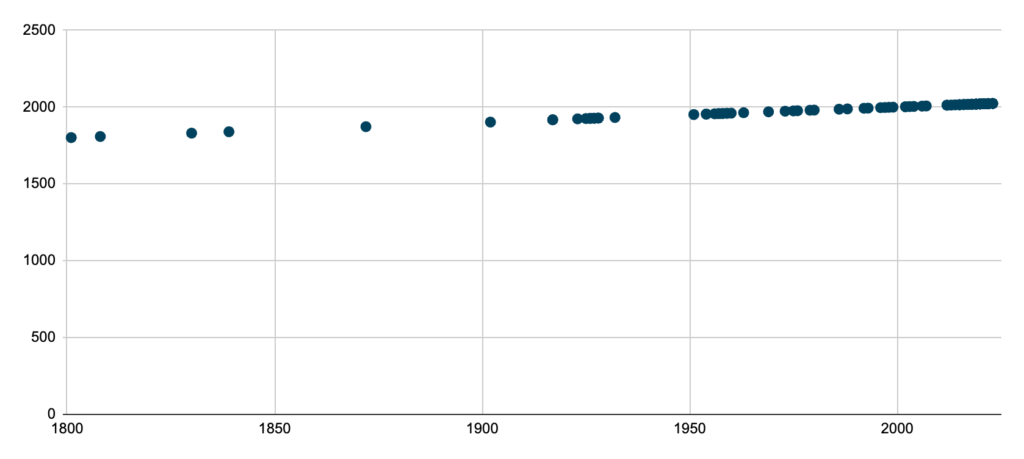
Als wir 2022 in Kooperation mit der Deutschen Nationalbibliothek das Projekt DisKo zum Aufbau eines Diversitätskorpus gestartet haben, war es unser Ziel, 100 Titel der letzten 100 Jahre zu sammeln, in denen ungewöhnliche Gender-Darstellungen vorkommen. Dazu haben wir ein Community-Projekt gestartet, an dem du dich auch heute noch hier beteiligen kannst. Im vergangenen Jahr 2024 haben wir die 100-Titel-Ziellinie überschritten. Allerdings haben wir bisher noch keine lückenlose Abdeckung von mindestens einem Titel pro Jahr, sondern – wie man in Abb. 1 sehen kann – Phasen, für die wir viele Titel haben und solche, in denen Lücken klaffen. Zum Beispiel haben wir noch keinen Titel, der zwischen 2007 und 2012 veröffentlicht wurde. Eine ziemlich große Lücke, die wir vielleicht auch gar nicht ganz schließen können, klafft zwischen 1928 und 1951, also in der Phase, in die auch der 2. Weltkrieg fällt. Über ungewöhnliche Gender haben in dieser Zweit zumindest im deutschsprachigen Raum Autor*innen wahrscheinlich eher nichts veröffentlichen können. Dennoch sammeln wir weiter, um so viele Lücken wie möglich zu schließen. Wenn dir also noch Titel einfallen, reiche sie gerne über unser Formular ein.
Kurzbeschreibungen für 101 DisKo-Titel
Wir haben es 2024 aber nicht nur geschafft, die 100-Titel-Ziellinie zu überschreiten. Wir haben auch für die meisten Titel, nämlich für stolze 101, kurze Beschreibungen auf unserer Webseite hinterlegt. Die Hauptarbeit hat dabei Lucy übernommen. Wenn man nun über einen Titel hovert, für den es eine Kurzbeschreibung gibt, so kann man in ca. 3 Sätzen nachlesen, worum es in einem Text geht und warum dieser Text für das Thema der ungewöhnlichen Gender-Darstellungen relevant ist. Ihr könnt also jetzt noch besser nach neuem Lesestoff stöbern, wenn ihr gerne Romane und Erzählungen lest, in denen untypische Darstellungen von Gender vorkommen. Auch wenn ihr euch literaturwissenschaftlich dafür interessiert, können euch die neuen Kurzbeschreibungen weiterhelfen.
Und was ist mit der digitalen Verfügbarkeit?
Wenn du allerdings – so wie wir – aus den digitalen Literaturwissenschaften kommst, so wirst du dich vielleicht fragen, inwiefern dir eine Liste helfen soll, die dich am Ende nicht unbedingt zu digital verfügbaren Texten führt. Da Texte, die in den letzten 100 Jahren publiziert wurden, mehrheitlich noch nicht frei verfügbar sind, können wir hier meist nicht viel mehr tun, als Titel und Beschreibungen zur Verfügung zu stellen. Da wir an dieser Stelle aber nicht aufhören wollen, haben wir 2024 begonnen, weiter in der Zeit zurück zu gehen und arbeiten nun an einer Ergänzung von DisKo, die ältere Titel umfasst – die DisKo-Classics. Nächstes Etappenziel sind erst einmal wieder 100 narrative Texte (Romane und Erzählungen), in denen Figuren mit ungewöhnlichen Gender-Profilen vorkommen.
DisKo-Classics – über 100 weitere Titel mit ungewöhnlichen Genderdarstellungen
Den Anfang für unsere Diversitätskorpus-Erweiterung DisKo-Classics bildeten natürlich Texte, die über das DisKo-Formular eingereicht wurden und die nicht in den Zeitrahmen 2024-1924 fallen. Derzeit sind das 8 Texte. Um auf 100 zu kommen, mussten wir also noch Einiges dazu recherchieren. Genutzt haben wir dazu 3 Strategien, mit denen wir gesucht haben nach
- Texten, die in Forschungsliteratur zu Gender Studies genannt werden
- Texten, die auf Blogs und ähnlichen Internetplattformen als queere Literatur eingestuft werden
- Texten, in denen mindestens eines aus einer Liste von Schlagwörtern mindestens ein Mal vorkam.
Auf diese Weise haben wir zunächst eine Liste mit potentiellen Kandidaten für DisKo Classics erstellt. Derzeit sind wir dabei, diese Kandidaten nach und nach zu prüfen. Das heißt wir lesen die Texte und entscheiden dann, ob die Repräsentation von Gender tatsächlich auf die eine oder andere Weise ungewöhnlich ist. Dabei hilft uns eine Liste mit Themen, die ungewöhnliche Varianten von Gender beinhalten. Diese Liste haben wir mithilfe von Forschungsliteratur erstellt. Darauf stehen z.B. Themen wie Androgynität, Trans- oder Intersexualität, Non-Binarität, Crossdressing und auch einfach ungewöhnliche Frauen- und Männerfiguren z.b. im Sinne von Dandyismus oder dem Phänomen der „New Woman“. Dass diese unterschiedlichen Varianten im Korpus repräsentiert sind, ist für uns so wichtig, da eines unserer m*w-Gesamtziele ist, ein Machine-Learning-Tool darauf zu trainieren, automatisch ungewöhnliche Darstellungen von Gender zu erkennen. Dafür brauchen wir für die unterschiedlichen Phänomen, die berücksichtigt werden sollen, möglichst hochwertige Annotationen. Diese zu erstellen war etwas, woran wir 2024 ebenfalls intensiv gearbeitet haben.
DisKo-Classics-Annotationen – komplette Texte im Gold-Standard annotiert
Seit Herbst 2024 habe wir in Stuttgart mit einem Team studentischer Mitarbeiterinnen begonnen, komplette Texte im Hinblick auf gegenderte Figurenreferenzen zu annotieren. Das bedeutet, dass wir einzelne Texte gelesen und alle Wörter darin markiert haben, die eine Figur bezeichnen. Jede in einer solchen Referenz enthaltene Gender-Information haben wir in den Annotationsdaten hinterlegt. Dabei richten wir uns nach sehr genauen Annotationsrichtlinien, die nicht nur auf bisheriger Forschung zu Gender basieren, sondern auch immer einmal wieder überarbeitet werden, wenn Zweifelsfälle auftreten.
Damit die Annotationen, mit denen wir am Ende weiterarbeiten besonders verlässlich sind, wird jeder Text von drei Annotierenden parallel und unabhängig voneinander anhand der Guidelines annotiert. Per Mehrheits-Entscheid erstellen wir dann einen Goldstandard, d.h. in die finale Annotation übernehmen wir die Annotationen, bei denen sich mindestens zwei aus dem Team der Annotierenden einig sind. Gibt es für einen Fall keine Mehrheit, so prüfen wir, also Marie oder ich, diese noch einmal gesondert. Auf diese Weise sind 2024 die ersten 8 Goldstandards für komplette Texte aus DisKo-Classics entstanden. Damit ist ein wichtiger Grundstein für das Gender-Profiling von Figuren gelegt, das wir im Rahmen einer Pilotstudie auf einer Konferenz in Italien 2023 schon einmal vorgestellt hatten. Mehr darüber findest du hier.
DisKo-Profiling – gegenderte Netzwerke und Gender-Profile
Wenn es um digitale Methoden in den Geisteswissenschaften geht, fällt öfter mal ein Stichwort: Komplexitätsreduktion. Häufig steht das im Zusammenhang mit einer Methodenkritik. Übersehen wird dabei nicht selten, dass Komplexität zwar auf auf einer Ebene reduziert wird, aber nur, um auf einer anderen Ebene mehr Komplexität zu erlauben. Bei uns bedeutet das, dass wir uns zwar zunächst einmal nur auf Nomen konzentrieren, mit denen Figuren bezeichnet werden und die Gender-Informationen enthalten. Dafür berücksichtigen wir aber für jede Figur jede Referenz und damit auch jede darin enthaltene Gender-Information. Sind die Texte entsprechend annotiert, so müssen wir natürlich die Referenzen und darin enthaltene Gender-Informationen noch mit einzelne Figuren verknüpfen. Das machen wir, indem wir anhand der Goldstandard-Annotationen Netzwerkdaten erstellen. In diesen Netzwerkdaten sind zum Teil äußerst komplexe Figuren-Profile enthalten, die sehr spezifische Muster von Gender-Darstellungen aufweisen. Die Netzwerkdaten erstellen wir manuell und verwenden auch darauf wieder große Sorgfalt. Seit Herbst 2024 sind für 6 Texte der DisKo-Classics-Erweiterung Netzwerkdaten erstellt worden.
2025: Ausbauen, vertiefen, öffnen
Wie du siehst, haben wir 2024 relativ viel hinter den Kulissen gemacht und relativ wenig davon gezeigt. Es gab keinen neuen Blogbeitrag und auch unsere Aktivitäten-Seite verzeichnet für 2024 nur zwei neue Einträge. Das soll sich in diesem Jahr ändern. Zwar arbeiten wir weiterhin daran, mehr Texte mit ungewöhnlichen Gender-Darstellungen zu sammeln, zu lesen, zu annotieren und dazu Gender-Profile zu erstellen. Allerdings wollen wir auch etwas mehr von unseren Arbeiten des vergangenen Jahres zeigen. Darum starten wir eine neue Blogartikel-Serie. Darin zeigen wir zu einzelnen Texten besonders interessante Erkenntnisse aus unseren Netzwerkanalysen und unserem Gender-Profiling. Mehr über diese Blogartikel-Serie und die Methoden die dahinter stehen, erfährst du schon am kommenden Montag, den 6.1.2025. Natürlich hier auf dieser Webseite. Wir freuen uns auf ein Jahr mit noch mehr Texten, noch mehr Annotationen und noch mehr Gender-Profilen und freuen uns, wenn ihr wieder mit dabei seid!


Das könnte dich auch interessieren

“Sich über die Liebe (…) selbst zu lieben”: zur Relevanz des Typus der Liebenden von Simone de Beauvoir

Tage im Leben von …