Netzwerkanalyse und warum sie erst in Verbindung mit anderen Methoden der digitalen Textanalyse ihr volles Potential entfaltet
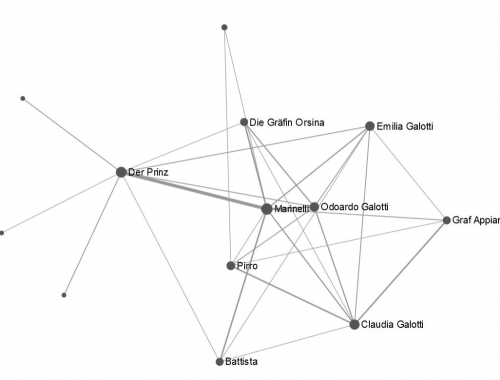
Ein Beitrag von Lea Röseler zur Netzwerkanalyse Netzwerkanalyse – Wenn A mit B spricht, aber nicht mit C Der wohl wichtigste Bestandteil literarischer Werke sind sicherlich die Figuren. Durch ihre Handlungen und Interaktionen bringen sie die Geschichte voran. Doch wie…
King Kong Theorie : das schonungslose feministische Manifest der subversiven französischen Autorin Virginie Despentes.
Ein Beitrag von Marie Tréfou über die King Kong Theorie In ihrem Buch King Kong Theorie (Despentes, 2018) bespricht Virginie Despentes unterschiedliche gesellschaftliche Themen wie Vergewaltigung, Prostitution und Pornographie. Sie beobachtet und analysiert und rückt dabei ohne Umschweife das kulturelle…
Sind Frauen auch heutzutage noch „das andere Geschlecht“?
Ein Beitrag von Annabelle Lange zu Simone de Beauvoirs „Das andere Geschlecht“ „Man kommt nicht als Frau zur Welt, man wird es.“ ist Simone de Beauvoirs (de Beauvoir, 2008) bekanntestes Zitat. Doch Wenige wissen, woher genau dieses Zitat stammt und…
“Sich über die Liebe (…) selbst zu lieben”: zur Relevanz des Typus der Liebenden von Simone de Beauvoir
Ein Beitrag von Nina Allaert zur Aktualität von Simone de Beauvoir “Was stimmt mit mir nicht, dass ich immer noch keinen Freund habe?” “Sag mal, das ist doch nicht mehr normal? Jetzt hat ausgerechnet Sara* auch schon ihren ersten Freund!…
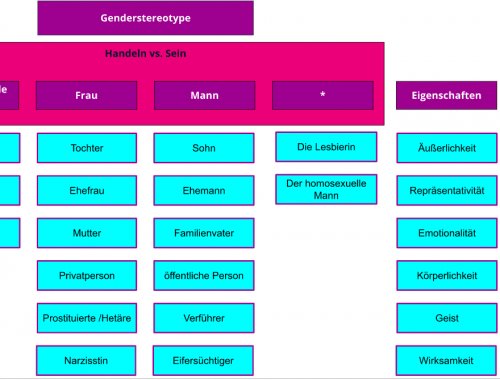
Genderstereotype in der Literatur – erste Analysen
Vierundzwanzig Novellen des deutschen Novellenschatzes wollen wir uns anschauen, um Genderstereotype in der Literatur des 19. Jahrhunderts besser zu verstehen. Um zu schauen, ob unser Konzept aufgeht, haben wir nun einen ersten Texttest analysiert; die drei Schwestern von Ludwig August…
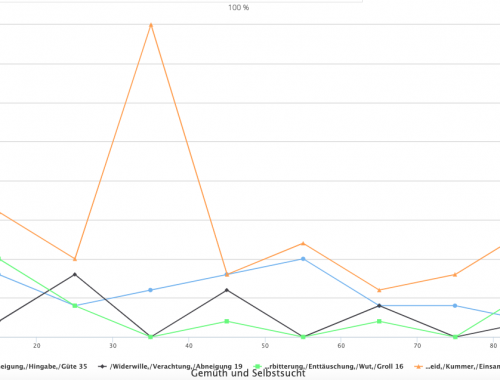
Emotionsinformationen analysieren: 3. Erste Ergebnisse – Gemüth und Selbstsucht (1787) von Margarethe von Wolff
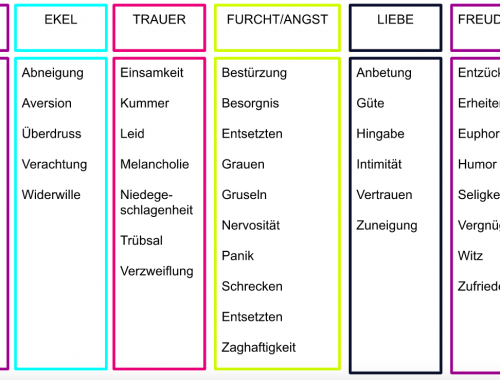
Für die Auswertung der Annotationen, die die Art der Emotion betreffen, haben wir für jedes Mitglied einer Emotionsfamilie eine Query verwendet, die die Anzahl der Tags anzeigt (Text ID 76, 20.954 Wörter, Annotation Collection Marie_Text 76). Im Text sehen die…
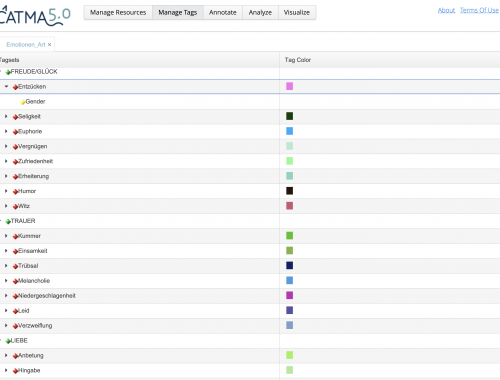
Emotionsinformationen analysieren: 2. Warum digital und warum CATMA?
An einigen Stellen des ersten Blogbeitrags war von sog. Tagsets und Annotationen die Rede. Beide Begrifflichkeiten spielen für unser Analyseverfahren eine tragende Rolle. Die Analyse des Deutschen Novellenschatzes führen wir mithilfe des Textanalysetools CATMA (Computer Assisted Text Markup and Analysis)…
Emotionsinformationen analysieren: 1. Forschungsüberblick und Definitionen
Der zweite Untersuchungsschwerpunkts von m*w fokussiert die Frage, welche Emotionen weiblichen, männlichen und diversen Figuren im Deutschen Novellenschatz zugeschrieben werden. Gibt es „typisch“ weibliche, männliche oder diverse Emotionen, sodass von einer stereotypen Genderdarstellung die Rede sein kann? Auf welche Art…
Automatische Erkennung von Figuren-Gender – das erste Modell
Heute teilen wir erste Ergebnisse unseres Modells zur automatischen Erkennung von Figuren-Gender.
m*w
Unser Thema Diskussionen über Männlichkeit, Weiblichkeit, Feminismus, Gendersternchen und -Lücken tauchen immer wieder in öffentlichen Diskussionen auf. Die Standpunkte in solchen Debatten werden meist vehement und emotional verteidigt. Meistens geht es darum, althergebrachte Rollenmuster entweder in Frage zu stellen oder…